2005年6月至2007年12月海洋表面洋流示意图。数据源:海面高度数据来自美国航空航天局(NASA)的Topex/Poseidon卫星、Jason-1卫星,以及海形图任务/Jason-2卫星测高仪;重力数据来自NASA/德国航空航天中心的重力恢复及气候实验任务;表面风压数据来自NASA的QuikScat任务;海平面温度数据来自NASA/日本宇宙航空研究开发机构的先进微波扫描辐射计-地球观测系统;海冰浓度和速度数据来自被动微波辐射计;温度和咸度分布来自船载、系泊式测量仪器,以及国际Argo海洋观测系统。 这幅2005年6月至2007年12月海洋表面洋流的示意图集成了带有数值模型的卫星数据。漩涡和窄洋流在海洋中传送热量和碳。海洋环流和气候评估项目提供了所有深度的洋流,但这里仅仅使用了表层洋流。这些示意图用来测量海洋在全球碳循环中的作用,并监测地球系统的不同部分内部及之间的热量、水和化学交换。 在医学领域,2003年算是大数据涌现过程中的一个里程碑。那一年第一例人类基因组完成了测序。那次突破性的进展之后,数以千计人类、灵长类、老鼠和细菌的基因组扩充着人们所掌握的数据。每个基因组上有几十亿个“字母”,计算时出现纰漏的危险,催生了生物信息学。这一学科借助软件、硬件以及复杂算法之力,支撑着新的科学类型。
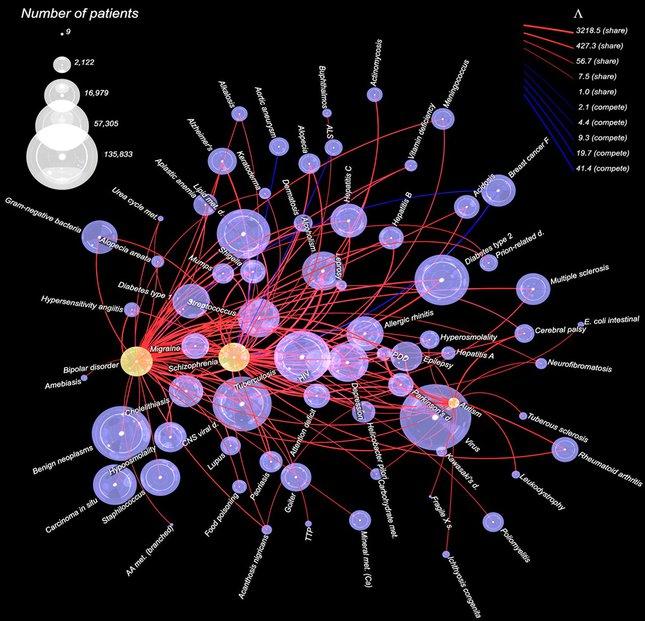
精神障碍通常是具体病例具体分析,但是一项对150万名病人病例的研究表明,相当多的病人患有超过同一种疾病。芝加哥大学的西尔维奥·康特中心利用数据挖掘理解神经精神障碍的成因以及之间的关系。“好几个(研究)团队都在致力于这个问题的解决。”中心主任安德烈·柴斯基(Andrey Rzhetsky)说,“我们正试图把它们全部纳入模型,统一分析那些数据类型……寻找可能的环境因素。” 图片来源:Andrey Rzhetsky,芝加哥大学 另一例生物信息学的应用来自美国国家癌症研究所。该所的苏珊·霍尔贝克(Susan Holbeck)在60种细胞系上测试了5000对美国食品和药品管理局批准的抗癌药品。经过30万次试验之后,霍尔贝克说:“我们知道每种细胞系里面每一条基因的RNA表达水平。我们掌握了序列数据、蛋白质数据,以及微观RNA表达的数据。我们可以取用所有这些数据进行数据挖掘,看一看为什么一种细胞系对混合药剂有良好的反应,而另一种没有。我们可以抽取一对观察结果,开发出合适的靶向药品,并在临床测试。” 互联网上的火眼金睛 当医学家忙于应对癌症、细菌和病毒之时,互联网上的政治言论已呈燎原之势。整个推特圈上每天要出现超过5亿条推文,其政治影响力与日俱增,使廉洁政府团体面临着数据挖掘技术带来的巨大挑战。 印第安纳大学Truthy(意:可信)项目的目标是从这种每日的信息泛滥中发掘出深层意义,博士后研究员埃米利奥·费拉拉(Emilio Ferrara)说。“Truthy是一种能让研究者研究推特上信息扩散的工具。通过识别关键词以及追踪在线用户的活动,我们研究正在进行的讨论。” Truthy是由印第安纳研究者菲尔·孟泽(Fil Menczer)和亚力桑德罗·弗拉米尼(Alessandro Flammini)开发的。每一天,该项目的计算机过滤多达5千万条推文,试图找出其中蕴含的模式。 |

最新评论
最新新闻










 /1
/1 

