一、业务背景 作业帮成立于2015年,一直致力于用科技手段助力教育普惠,运用人工智能、大数据等前沿技术,为学生、老师、家长提供更高效的学习、教育解决方案,智能硬件产品等。作为大数据中台架构团队,我们一直探索利用有限的资源,较低的开发维护成本、高时效的数据更新和查询,为业务团队提供基础支持。
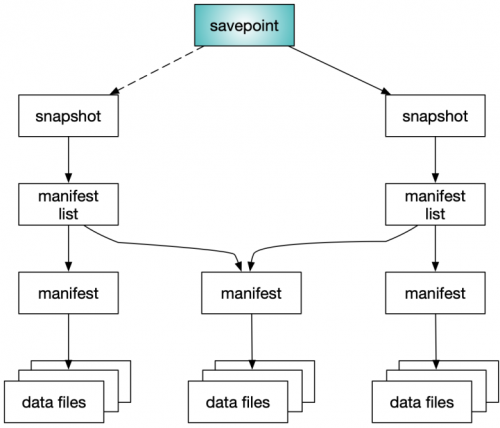
二、问题&痛点 1.ODS层数据就绪时间晚,DWS/ADS等上层数据和业务报表构建时间少 作业帮ODS层表大概有几千张,TP90就绪时间大概在4点30左右,不同业务团队因工作时间不同,看数时间会有些差异,总体上来说基本都要求数据10点前就绪。这样留给上层数仓及报表数据构建时间大概6小时,随着上层数据看数丰富度增加,在资源不变的情况下,减少ODS层就绪时间将可以给上层数据构建争取更多时间。 2.基于hive的离线数据新鲜度弱,基于Kafka的实时数据构建和维护成本高 目前基于Hive的离线数据多为T+1天时效性,较少部分为T+1小时且多为流量数据。针对核心转化类数据可分析价值更高,目前多以Kafka为介质构建实时数据,但对数、刷数、ExactlyOnce保障、join等场景数据构建和维护成本高。如果可以通过类似Hive sql构建准实时数据,业务可以更容易获得高新鲜度的数据进行分析。 3.业务查数速度慢,分析效率低 业务基本都是基于DWS/ADS等上层数据进行分析,经过分析历史sql发现查询所用维度相对固定,面对大表加载数据仍然是主要耗时点,这个过程业务老师基本都是处于等待状态,工作效率出现明显瓶颈。 三、基于Iceberg承载批流一体实现数据“仓转湖”探索 考虑到Iceberg优雅的架构设计、相对开放和完备的数据格式定义,有较强的可塑性和扩展能力更方便进行特定场景的优化。同时腾讯云EMR团队针对Iceberg在计算框架适配、性能等方面做了优化。所以我们选择Iceberg来承载批流一体实现数据“仓转湖”探索。 作业帮数据仓库ODS层构建都是由数据中台来完成,我们把ODS层作为切入点来逐步引入Iceberg,因流量侧ODS层数据量相对较大,在场景和性能方面探索的代表性更全,最终决定用此部分数据作为探索数据,同时需要探索以下关键问题的解决方式: 1.数据流转批:数据湖仓共存,以减少对上层业务使用的影响。 2.表格式无缝迁移:解决云上环境Hive表格式迁移Iceberg的诸多问题。 3.查询性能提升:改进传统Hive特定高频分析场景时间过长的问题。 四、流数据转批 基于Hive+COS 构建的ods表都是按照天级别或小时级别来构建。DWD层的任务均是按照ODS层的表分区是否就绪来触发的。这个场景在Hive上实现很简单,因为Hive 天然支持按照日期字段进行分区。但切换成Iceberg 表后,通过Flink 实时写入的数据,已经commit的snapshot所包含的数据就可读。Iceberg提供的这种边写边读的能力在构建实时数仓的过程中非常有用,但这种能力在我们实际切换过程中成为了卡点,因为我们必须保证ODS层某天的数据完全就绪后,才能对外提供对应天级别的查询能力。 基于这样的需求,我们在Iceberg中引入savepoint 概念,即基于事件时间的快照点。下图展示了新的元数据设计:
本质上,每个savepoint也是一个snapshot。但不一样的是,savepoint是根据数据的事件时间生成。举一个简单的例子:随着数据的不断摄入,Iceberg表生成了若干个连续的snapshot,但只有在整点时刻(例如按小时间隔)才会生成一个savepoint。区别于传统的基于snapshot的数据查询机制,我们从savepoint中进行数据查询。由于savepoint是根据事件时间周期(例如按小时间隔)生成的,只有当Iceberg表的小时段数据写入完成,上层业务才可以查询对应的分区数据。下图演示了各种查询条件下的数据可见性情况:
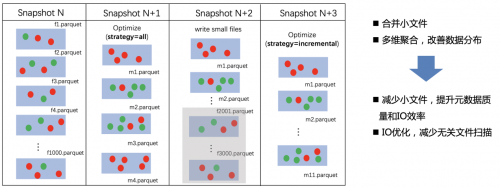
其中: Query 1和6只能查到天级别的完整数据 Query 2,3,4和5只能查到小时级别的完整数据 基于以上设计,我们可以实现上层T+1的表数据构建业务无缝透明地从Hive迁移到Iceberg上,并且不会对业务使用方带来任何的理解偏差。 五、Hive表格式无缝迁移 作业帮数据中台持续的为多个业务线提供数据支撑,在引入Iceberg之前已存在大量的Hive表供各个业务方使用。作为底层数据提供方,不可能因为要引入一项新的技术,就让下游业务使用方跟着做改动,所以我们需要让下游业务方查询时并不关心查询的是Hive表还是Iceberg表,对业务方透明。基于这样的诉求,我们需要将Hive表无缝转化成Iceberg表。 Iceberg社区提供了表格式迁移工具,即migrate工具。它通过构建Iceberg所需的元数据来实现Hive表格式转换,避免了数据的导出导入成本。不过在实际使用中还是在一些特定场景下的不兼容问题: 1.作业帮的离线数据全部存储在COS中,并且根据一定的规则,这些COS数据会进行逐级冷处理,即从标准存储类型转换成归档存储类型。但开源大数据数据接口的事实标准不支持COS归档存储,导致Iceberg表格式迁移工具无法正常使用。 2.作业帮的Hive表分区目录存在多级子目录。Iceberg表格式迁移工具不支持分区目录的子目录结构,导致在生成manifest元数据时会丢失大量的数据文件记录。 3.作业帮的Hive表存量数据非常大,甚至有PB级别。社区版迁移工具的文件处理能力有限,针对这种超大规模表迁移耗时会非常长。 针对这些云上特定场景,腾讯云EMR对Iceberg迁移工具进行了兼容适配和优化: 1.兼容归档存储类型。当归档文件转标准文件之后,支持通过工具修正manifest元数据。 2.兼容分区子目录结构。 3.支持executor-side的文件处理能力,更高的并发能力,更快的迁移速度。 基于以上优化,我们可以快速高效地实现将COS中的Hive表迁移到Iceberg上。 六、查询性能提升 ODS层的数据多是一些结构化的原始数据,DWD层是基于ODS层来筛选出不同主题的数据,这种模式下,不管某个主题筛选的数据量多少,都需要扫描ods层的全部文件,过滤出符合条件的数据。这种模式不仅会产生大量无用的IO操作,还浪费资源,查询性能差。 基于这样的诉求,我们使用Z-Order数据重排来减少查询时无用的文件扫描。Iceberg在数据查询时会使用data-skipping技术,跳过那些不存在目标数据的文件,从而节省IO带来查询提升。但实际使用中,data-skipping技术发挥的余地会非常小。这是因为数据的某种“无序”分布,导致查询条件的目标数据会分布在大部分文件甚至所有文件,这就导致简单的查询需要扫描全表的原因。Z-Order是一种数据组织算法,它可以实现按照给定字段(即Z-Order字段)的数据聚集性或者说局部性。经过Z-Order之后的表数据文件会呈现比较明显的可区分度,这样根据Z-Order字段的查询会略过大量的无关文件。
ZOrder天然地也会进行小文件合并。小文件合并以及数据组织优化两个方面共同实现提升查询性能的目的。我们结合作业帮业务场景进行了性能评估。 1.集群配置:10台 8核32GB、500GB 云SSD 2.SSB Scale:100
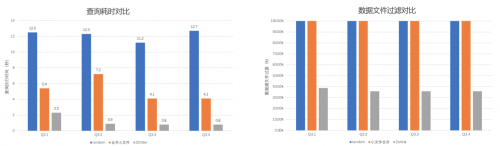
对比原始表和小文件合并,性能提升是非常大的,一个主要优化点就是过滤了大量无用文件扫描。基于以上优化,我们在生产环境中的查询性能也得到了成倍提升。 除了以上工作,腾讯云EMR团队联合作业帮还对Iceberg进行了如下特性开发和内核优化: 1.支持Hive on Spark写入Iceberg表 2.Hive查询支持Map类型的Filter下推 3.Z-Order 索引构建优化和复杂数据类型支持 4.优化数据倾斜场景Z-Order的数据构建性能 5.外部Metastore:支持Iceberg表元数据同步到外部DB 七、总体效果 基于这些特性和优化,作业帮开展部分流量表进行灰度实验。通过本次灰度,我们实现了: 1.存储格式切换为Iceberg能力,上层业务无成本迁移。上层业务对底层存储升级的无感切换:业务表没有任何改造成本,数据表的业务理解无任何变化等等。 2.基于Z-Order优化,查询性能获得提升。对于那些分析重度使用的表,通过迁移到Iceberg并做了Z-Order优化后,查询性能得到几倍甚至几十倍的提升,查询时间下降到分钟级。 3.数据分区时效性提高。通过Flink流式写入数据,实时生成Savepoint,从而实现真实数据就绪的近实时。 4.元数据接入更加便捷。腾讯云EMR提供的Iceberg外部Matastore功能降低了作业帮元数据采集和查询的成本,几乎零改造实现Iceberg元数据接入。 八、探索的意义 作业帮离线数仓是基于腾讯对象存储cos + EMR存算分离的方式来落地的,实时数仓多以Flink+Kafka方式落地的,虽然可以解决业务对数据的诉求,但是也引入了其他问题例如实时数据故障排查难、可靠性不易实现、开发维护成本高,离线数据增量计算支持弱、查询速度慢、数据时效性低,离线实时对数难等问题。 数据湖技术在原理层面看是可以帮助我们缓解以上问题的,同时数据湖发展已有一段时间各种功能也逐步支持,但对于作业帮而言还缺乏更深入的认识,此次探索模拟了部分迁移过程可能遇到的技术问题、业务感知、功能匹配度进行了摸底灰度测试,为最终的湖仓一体化建设提供了较高的参考价值。 九、未来规划 下一阶段,作业帮将联合腾讯云EMR团队探索解决以下一些问题: 1.运维成本高:不管是快照清理还是Z-Order优化,都需要手动配置,运维成本高。 2.多引擎支持:当前部分新特性支持了Hive,Spark和Flink引擎,但trino等引擎没有完全支持。 3.Z-Order列选举门槛高:需要业务侧参与配合完成Z-Order优化工作,往往业务侧也不是很清楚选举那些列进行Z-Order比较合适,这就有可能导致Z-Order选择不对,对业务查询提升无意义,平白增加额外计算开销。 4.无法构建基于Iceberg的流式pipeline:缺少关键的表间CDC能力。 |

最新评论
最新新闻










 /1
/1 

