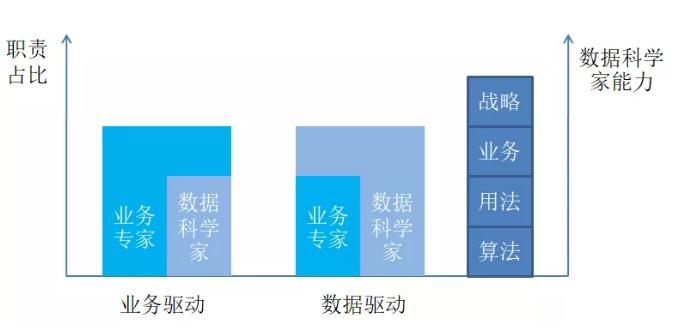
01 数据科学家的工作模式与组织结构 数据科学家需要与业务专家一起工作才能发挥最大价值。实际工作中两种角色如何配合,取决于是采用业务驱动的模式还是数据驱动的模式。 1. 数据驱动还是业务驱动 业务驱动的特点是业务人员主导数据分析需求的提出、结果的应用,在业务中应用数据洞察;而数据驱动的特点是更看重主动应用数据分析手段,从数据洞察发起业务、改善业务,当然在业务执行时也需要广泛应用数据洞察。在较新的业务领域采用数据驱动比较适合,已有复杂业务则采用业务驱动较好。 然而从自身能力的发展、数据驱动逐渐成为主要的工作模式的情况来看,数据科学家需要思考如何将数据驱动的模式做得更好,并且愿意承担更多责任。所以,除了算法、用法等基本技能,还需要考虑如何改善业务。 下图所示的职责占比只是示意,其实最核心的是由哪种角色来主导,在工作中也未见得业务专家不能主导数据驱动的模式。从业务结果的角度来看,所谓业务驱动和数据驱动只是到达一个既定目标时不同的工作方式而已。在实际的业务中也不会分工非常明确,即不会限定业务人员只能做什么或数据科学家只能做什么,只有相互无缝协作才是最佳的工作模式。
▲业务专家与数据科学家的两种配合方式 2. 数据科学家团队的组织结构 数据科学家团队的组织结构关系到数据应用的效率、管理的效率、个人的发展等诸多方面,企业在设置这个组织结构时需要认真考虑。每个企业的实际情况不同,可以采用不同的方法。数据科学家的组织结构一般分两种,即分散式结构和集中式结构。 分散式结构是数据科学家属于确定的业务部门,这样的组织结构的好处是其可以紧密地与业务人员合作,将业务问题转换为高效的数据分析任务。 但是其也有不足,一方面数据分析的知识积累是在个人身上,而不是在团队,另外一方面就是因为角色的限制使得业务部门内的数据科学家没有上升空间。业务部门内的数据科学家若要在职业道路上继续前进,要么离开,要么担任其他角色。一旦发生数据科学家的人事变化,这对团队稳定、知识积累等都是不利的。 集中式的数据科学家组织结构就是跨业务条线而成立独立的专门做数据分析的结构。这样的组织结构的好处就是团队相对稳定,给成员提供了不断成长的空间,也避免了知识积累的流失。 但是其也有不足,由于数据科学家脱离业务部门而独立存在,导致团队成员对业务的理解不够深入,模型的产出可能效率低下。业务部门也可能只将其看作支持部门,而不会在实际业务中有太多引入。 企业在构架数据科学家组织架构时,也可采用混合的结构。即使是集中式的组织结构,其汇报的层级也可能不同。没有所谓明确的业界标准的说法,因地制宜的做法才是最实际的。
02 数据科学家的工作方法要点 数据科学家的核心任务之一是通过数据分析手段将数据洞察应用在实际业务中,并能产生有效的结果。数据科学家在实际工作中需要注意以下要点,以确保上述目标的达成。 1. 开始工作以前确保具备成功要件 在开始一件工作前,最好先明确一下业务场景、数据可获得性、数据质量等重要信息。在很多情况下,会出现因数据不支持无法进行细致分析、模型结果很好但是落地应用时没有对应的资源支持、数据分析只是探索没有对应的使用场景等问题。这些因素会严重影响数据分析的价值。 笔者作为顾问给多个客户实施数据分析项目时,就遇到过上述的问题。从客户的角度来讲,其关心的是业务问题的解决,并不会过多细致地考虑实施过程的细节。只有努力地尝试去做,才能发现有些问题会严重阻碍数据分析的进行,这也会影响数据分析的最终效果。 2. 同时输出两种价值 假设要通过数据分析手段改善某业务问题,如构建预测模型筛选高价值、高响应率的客户,即使是在目标非常明确的情况下,数据科学家也要在做的过程中保证两种输出结果。 (1)重要发现 数据分析过程中势必要进行数据提取、数据处理、数据探查等一系列基础工作。在这些基础工作的过程中,往往会隐藏着有巨大业务价值的信息。比如,笔者的团队在给某金融机构构建高端客户的相关模型时发现一些信息,如“大部分客户只持有一类理财产品且在半年内没有交易活动”,这些信息对于后期的营销策略制定至关重要。 所以,数据科学家在实际工作中需保持“业务敏感性”,对于数据背后的业务故事保持好奇心,同时将一些重要的数据发现协同模型结果一并输出,这可以大大提高分析主题的价值。 (2)模型结果 给定分析主题,目标模型结果就可以基本确定,如寻找高价值客户就是模型输出一个名单,风险预警就是给出风险评分以及原因。这是模型输出的最基本形式。 在实际的模型实施应用中,业务人员会经常以挑剔的眼光来看待模型,并且基于模型结果总是有不同的疑惑需要数据科学家来解答。典型的疑惑如“聚类分析模型确实将客户分了几个类别,但是我还是不知道该如何营销这些客户”“社交网络分析模型给出了潜在的高价值客户名单,但这些信息不足以让营销人员开展营销”。 出现这种情况时,一种简单的做法就是和业务人员深入讨论,梳理出他们的关注点,然后将对应的指标从数据库中提取出来,作为模型输入的补充一并交给业务人员。 从本质上来讲,出现业务人员疑惑的原因是“业务人员期待模型输出决策而不是名单”以及团队缺乏将模型输出转换为营销决策的能力。数据科学家也需要具备将模型结果转换为业务决策的能力。
3. 充满想象力地开展工作 算法能做到什么是数学范畴的知识,数据科学家的核心工作就是将业务需求转换为一系列的数据分析实践过程。若将各个算法看作一个个组件,那么用一个算法来解决问题还是用多个算法的组合来解决问题,需要数据科学家的想象力和不断尝试。 笔者的团队曾给某客户构建模型时,其需求是“根据客户持有产品的现状推荐产品,达到交叉销售的目的”。这是一个非常不具体的需求,能做的范围很大,能用的算法工具也很多。 最后我们采用的是构建“客户聚类与产品聚类的交叉分布以及迁移矩阵,并据此来展开不同目的营销”,若向上销售则可推荐同类产品,交叉销售则可推荐不同类的产品。这种做法之前没有实施过,但是结果证明其非常有效,仅在一次营销应用中就带来数十亿的营业额。 |








 /1
/1 

