| Hadoop已经通过自身的蓬勃发展证明,它不仅仅是一套用于将工作内容传播到计算机群组当中的小型堆栈--不,这与它的潜能相比简直微不足道。这套核心的价值已经被广泛证实,目前大量项目如雨后春笋般围绕它建立起来。有些项目负责数据管理、有些负责流程监控、还有一些则提供先进的数据存储机制。
Hadoop业界正在迅速发展,从业企业拿出的解决方案也多种多样,其中包括提供技术支持、在托管集群中提供按时租用服务、为这套开源核心开发先进的功能强化或者将自有工具添加到方案组合当中。 在今天的文章中,我们将一同了解当下Hadoop生态系统当中那些最为突出的杰作。总体而言,这是一套由众多工具及代码构成的坚实基础、共同聚集在"Hadoop"这面象征着希望的大旗之下。 Hadoop
虽然很多人会把映射与规约工具广义化称为Hadoop,但从客观角度讲、其实只有一小部分核心代码算是真正的Hadoop。多个工作节点负责对保存在本地的数据进行功能执行,而基于Java的代码则对其加以同步。这些工作节点得到的结果随后经过汇总并整理为报告。第一个步骤被称为"映射(即map)",而第二步骤则被称为"规约(reduce)"。 Hadoop为本地数据存储与同步系统提供一套简化抽象机制,从而保证程序员能够将注意力集中在编写代码以实现数据分析工作上,其它工作交给Hadoop处理即可。Hadoop会将任务加以拆分并设计执行规程。错误或者故障在意料之中,Hadoop的设计初衷就在于适应由单独设备所引发的错误。 项目代码遵循Apache许可机制。 官方网站:hadoop.apache.org Ambari
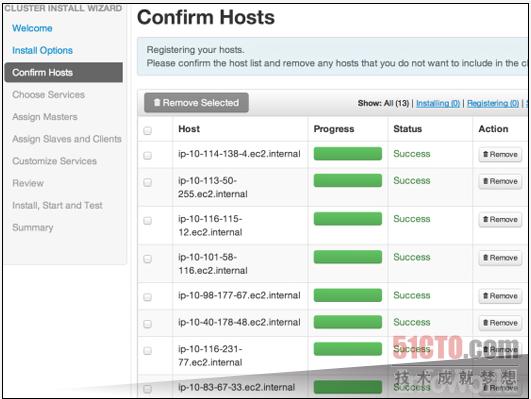
Hadoop集群的建立需要涉及大量重复性工作。Ambari提供一套基于Web的图形用户界面并配备引导脚本,能够利用大部分标准化组件实现集群设置。在大家采纳Ambari并将其付诸运行之后,它将帮助各位完成配置、管理以及监管等重要的Hadoop集群相关任务。上图显示的就是集群启动后Ambari所显示的信息屏幕。 Ambari属于Apache旗下的衍生项目,并由Hortonworks公司负责提供支持。 下载地址:http://incubator.apache.org/ambari/ HDFS (即Hadoop分布式文件系统)
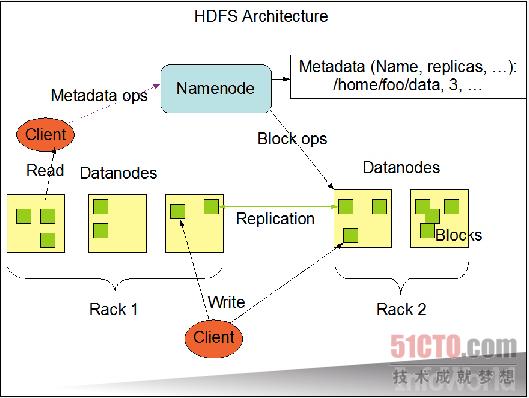
Hadoop分布式文件系统提供一套基础框架,专门用于拆分收集自不同节点之间的数据,并利用复制手段在节点故障时实现数据恢复。大型文件会被拆分成数据块,而多个节点能够保留来自同一个文件的所有数据块。上图来自Apache公布的说明文档,旨在展示数据块如何分布至各个节点当中。 这套文件系统的设计目的在于同时实现高容错性与高数据吞吐能力的结合。加载数据块能够保持稳定的信息流通,而低频率缓存处理则将延迟降至最小。默认模式假设的是需要处理大量本地存储数据的长时间作业,这也吻合该项目所提出的"计算能力迁移比数据迁移成本更低"的座右铭。 HDFS同样遵循Apache许可。 官方网站:hadoop.apache.org HBase
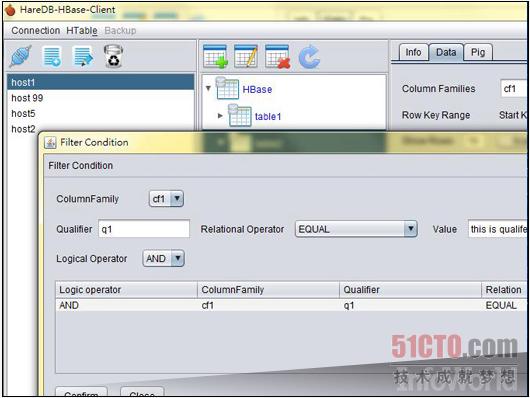
当数据被汇总成一套规模庞大的列表时,HBase将负责对其进行保存、搜索并自动在不同节点之间共享该列表,从而保证MapReduce作业能够以本地方式运行。即使列表中容纳的数据行数量高达数十亿,该作业的本地版本仍然能够对其进行查询。 该代码并不能提供其它全功能数据库所遵循的ACID保证,但它仍然为我们带来一部分关于本地变更的承诺。所有衍生版本的命运也都维系在一起--要么共同成功、要么一起失败。 这套系统通常被与谷歌的BigTable相提并论,上图所示为来自HareDB(一套专为HBase打造的图形用户界面客户端)的截图。 官方网站:hbase.apache.org |











 /1
/1 

