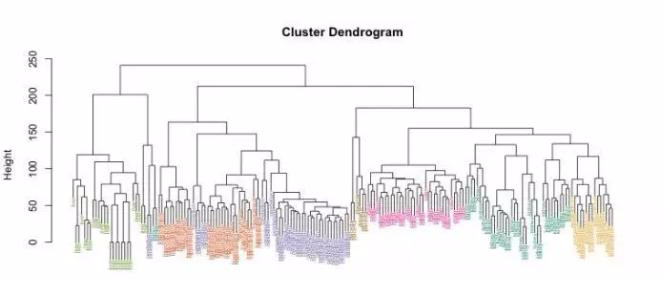
聚类算法十分容易上手,但是选择恰当的聚类算法并不是一件容易的事。 数据聚类是搭建一个正确数据模型的重要步骤。数据分析应当根据数据的共同点整理信息。然而主要问题是,什么通用性参数可以给出最佳结果,以及什么才能称为“最佳”。 本文适用于菜鸟数据科学家或想提升聚类算法能力的专家。下文包括最广泛使用的聚类算法及其概况。根据每种方法的特殊性,本文针对其应用提出了建议。 四种基本算法以及如何选择 聚类模型可以分为四种常见的算法类别。尽管零零散散的聚类算法不少于100种,但是其中大部分的流行程度以及应用领域相对有限。 基于整个数据集对象间距离计算的聚类方法,称为基于连通性的聚类(connectivity-based)或层次聚类。根据算法的“方向”,它可以组合或反过来分解信息——聚集和分解的名称正是源于这种方向的区别。最流行和合理的类型是聚集型,你可以从输入所有数据开始,然后将这些数据点组合成越来越大的簇,直到达到极限。 层次聚类的一个典型案例是植物的分类。数据集的“树”从具体物种开始,以一些植物王国结束,每个植物王国都由更小的簇组成(门、类、阶等)。 层次聚类算法将返回树状图数据,该树状图展示了信息的结构,而不是集群上的具体分类。这样的特点既有好处,也有一些问题:算法会变得很复杂,且不适用于几乎没有层次的数据集。这种算法的性能也较差:由于存在大量的迭代,因此整个处理过程浪费了很多不必要的时间。最重要的是,这种分层算法并不能得到精确的结构。 同时,从预设的类别一直分解到所有的数据点,类别的个数不会对最终结果产生实质性影响,也不会影响预设的距离度量,该距离度量粗略测量和近似估计得到的。 根据我的经验,由于简单易操作,基于质心的聚类(Centroid-based)是最常出现的模型。 该模型旨在将数据集的每个对象划分为特定的类别。 簇数(k)是随机选择的,这可能是该方法的最大问题。 由于与k最近邻居(kNN)相似,该k均值算法在机器学习中特别受欢迎。
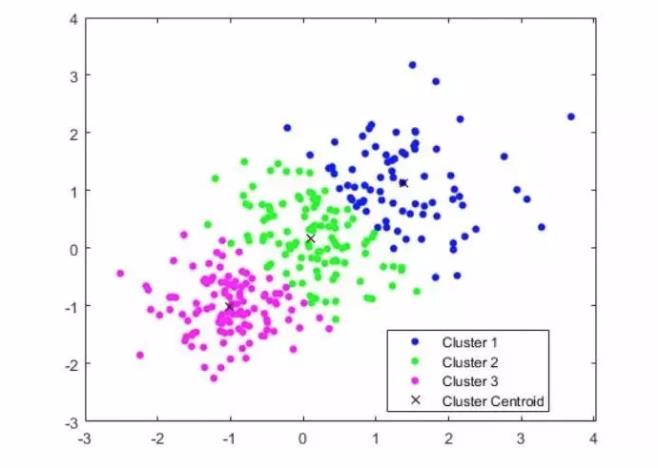
计算过程包括多个步骤。首先,输入数据集的目标类别数。聚类的中心应当尽可能分散,这有助于提高结果的准确性。 其次,该算法找到数据集的每个对象与每个聚类中心之间的距离。最小坐标距离(若使用图形表示)确定了将对象移动到哪个群集。 之后,将根据类别中所有点的坐标平均值重新计算聚类的中心。重复算法的上一步,但是计算中要使用簇的新中心点。除非达到某些条件,否则此类迭代将继续。例如,当簇的中心距上次迭代没有移动或移动不明显时,聚类将结束。 尽管数学和代码都很简单,但k均值仍有一些缺点,因此我们无法在所有情景中使用它。缺点包括:
https://www.encyclopedia.com/science-and-technology/mathematics/mathematics/normal-distribution#3 http://www.mastersindatascience.org/careers/data-scientist/
|

最新评论
最新新闻









 /1
/1 

