| 谈到大数据,必然会说到大数据四个特点:第一,数据体量巨大。从TB级别,跃升到PB级别;第二,数据类型繁多。网络日志、视频、图片、地理位置信息等等。第三,价值密度低。以视频为例,连续不间断监控过程中,可能有用的数据仅仅有一两秒。第四,处理速度快。最后这一点也是和传统的数据挖掘技术有着本质的不同。业界将其归纳为4个“V”——Volume,Variety,Value,Velocity。 不知道外界怎么看4个V,我总是记不住,也还是没有清楚何为大数据。其实,举一个例子就明白了,搜索引擎就是典型的大数据应用。与传统行业相比,互联网在大数据应用上的确领先,如电商,以及互联网广告等,都是典型的大数据应用,推动了互联网业务向精细化发展。互联网大数据应用技术细节披露甚少,而且多局限在行业内部,因此了解互联网行业大数据应用方式,将有助于我们把握问题的方向。 搜索引擎从本质上看,就是一种典型的大数据应用。在此,我们不妨以灵玖软件以ICTCLAS((Institute of Computing Technology, Chinese Lexical Analysis System,汉语词法分析系统)为基础推出的JZSearch大数据搜索引擎为例进行说明,参见JZSearch的技术框架如下:
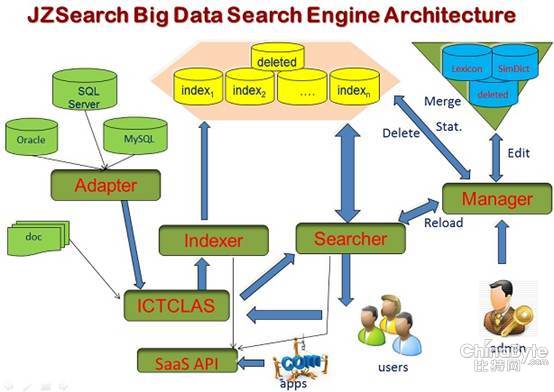
JZSearch大数据搜索引擎系统架构 从中,我们可以很容易了解到搜索引擎是如何将文档等非结构化化海量数据,通过建立索引来对外提服务的,其核心就是汉语词法分析系统(ICTCLAS),通过对自然语言、数字、日期、字符串等进行检索,建立索引。当用户进行检索时,基于索引,搜索引擎将这些数据聚合,提供给用户,从而构建了搜索引擎的服务。 与ICTCLAS稍有不同,传统搜索引擎,通过蜘蛛爬虫获取互联网Web网页的内容,构建索引库。借助类似Map/Reduce这样工具,搜索引擎可以对爬虫数据进行并行的处理。ICTCLAS与之相比,仅仅是针对的数据来源不同,搜索引擎针对网页的Web内容,ICTCLAS强调Doc等文档数据;通常文档数据是用户自己,当然也可以来自网上公开的内容,而搜索引擎的内容是爬虫“扒窃”来的,这也是为什么,Google被网站称为“寄生虫”和“吸血鬼”的原因,搜索引擎不创造任何内容,而是寄生在别人(网站)所创造的原创,内容上。“我们痛恨Google、百度,但另外一方面,我们又求助他们来抓取我们的内容,这是我们的悲哀。”网站CEO表示。 搜索引擎符合大数据的4个A:1、数据量大,每时每刻抓取网站原创内容(包括我现在写的,上线就会被抓取);2、类型多样,包括文本、图片、声音和视频;3、价值密度低(相对于财务、销售等结构化数据),需要挖掘才能够产生价值;4、处理速度快,对这些数据进行处理,可以采用大量廉价的X86服务器并行处理,也就是Map的过程;检索的结果,通过Reduce聚合后提供读者,由于大量机器并行,且通常检索索引,因此速度可以满足需求。 搜索引擎通过聚焦“眼球”,构建了以眼球货币为主的商业模式。而对于传统行业用户来说,如何利用和挖掘大数据的价值,这就是一个话题。当然,也可以利用搜索引擎,问题在于,搜索引擎所建立的索引,能够满足行业业务的需求和判断吗? “对于行业大数据而言,就是如何处理大数据,为行业业务应用创造价值。”业内资深人士对我说。 |










 /1
/1 

