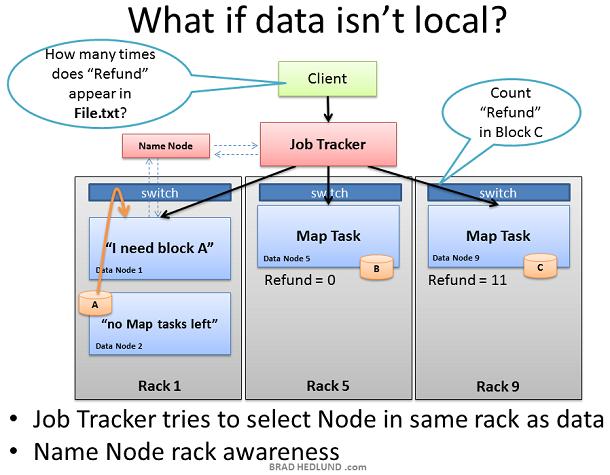
另外一种情况是Name node的Rack Awareness信息提供的网络优化行为。当Data node向Name node查询数据块位置信息,Name node优先查看请求者所在的机架内的Data nodes包含这个数据块。如果包含,那么Name node把这个Data node提供给请求的Data node。这样可以保证数据仅在in-rack内流动,可以加快数据的处理速度以及job的完成速度
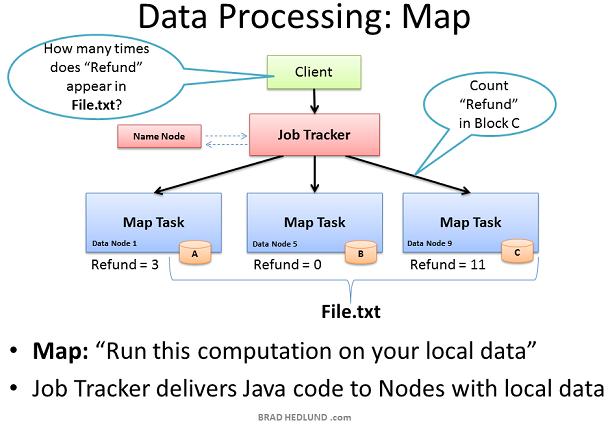
现在File.txt分散到集群的机器中这样就可以提供更快更有效的并行处理速度。Hadoop并行处理框架称为Map Reduce,名称来自于并行处理的两个重要步骤:Map和Reduce 第一步是Map 过程,这个步骤同时请求所有包含数据的Data node运行计算。在我们的例子中则是请求这些Data node统计存储在他们上的File.txt数据块包含多少此Refund 要达到这个目的,Client首先提交Map Reduce job给Job tracker,发送请求:“How many times does Refund occur in file.txt”。Job tracker向Name node查询哪些Data nodes包含文件File.txt的数据块。然后Job Tracker在这些Data nodes上运行Java代码 在Data node的本地数据上执行Map计算。Task Tracker启动一个Map task监测这些tasks的执行。Task Tracker通过heartbeats向Job Tracker汇报task的状态。 当每一个Map task都完成后,计算结果保存在这些节点的临时存储区内,我们称之为"intermediate data"。下一步是把这些中间数据通过网络发送给运行Reduce的节点以便完成最后的计算。
Job tracker总是尝试选择包含待处理数据的Data node做Map task,但是有时不会这样。比如,所有包含这块数据的Data node已经有太多的tasks正在运行,不再接收其他的task. 这种情况下,Job Tracker将询问Name node,Name node会根据Rack Awareness建议一个in-rack Data node。Job tracker把task分配给这个in-rack Data node。这个Data node会在Name node的指导下从包含待处理数据的in-rack Data node获取数据。
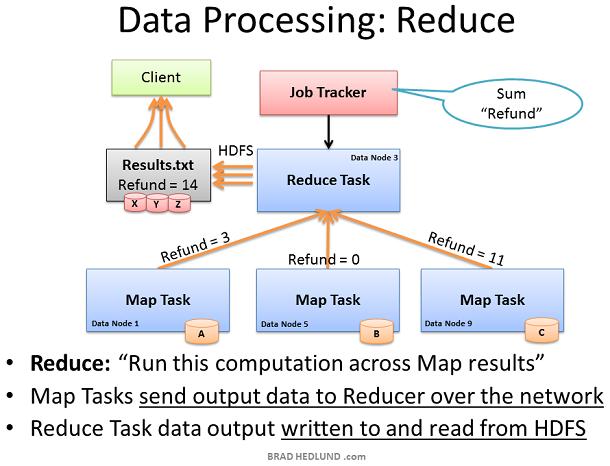
Map Reduce 框架的第二部分叫做Reduce。Map task已经完成了计算,计算结果保存在intermediate data。现在我们需要把所有的中间数据汇集到一起作进一步处理得到最终结果。 Job Tracker可以在集群内的任意一个node上执行Reduce,它指导Reduce task从所有完成Map trasks的Data node获取中间数据。这些Map tasks可能同时响应Reducer,这就导致了很多nodes几乎同时向单一节点发起TCP连接。我们称之为incast或者fan-in(微突发流)。如果这种微突发流比较多,那么就要求网络交换机有良好的内部流量管理能力,以及相应的buffers。这种间歇性的buffers使用可能会影响其他的网络行为。这需要另开一篇详细讨论。 Reducer task已经收集了所有intermediate data,现在可以做最后计算了。在这个例子中,我们只需简单的把数字相加就得到了最终结果,写入result.txt 我们的这个例子并没有导致很多的intermediate data在网络间传输。然而其他的jobs可能会产生大量的intermediate data:比如,TB级数据的排序,输出的结果是原始数据集的重新排序,结果尺寸和原始文件大小一致。Map Reduce过程会产生多大的网络流量王权依赖于给定的Job类型。 如果你对网络管理很感兴趣,那么你将了解更多Map Reduce和你运行集群的Jobs类型,以及这些Jobs类型如何影响到网络。如果你是一个Hadoop网络的狂热爱好者,那么你可能会建议写更好的 Map Reduce jobs代码来优化网络性能,更快的完成Job
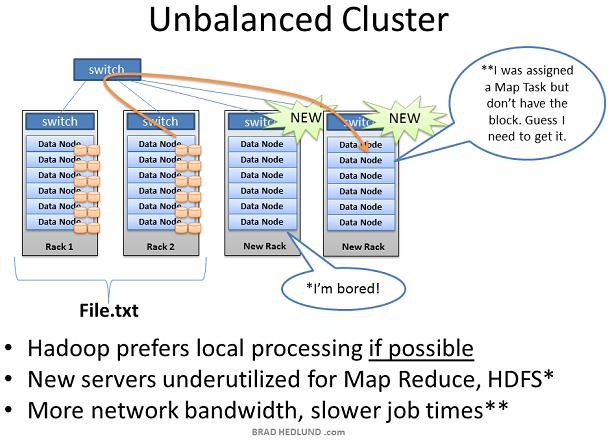
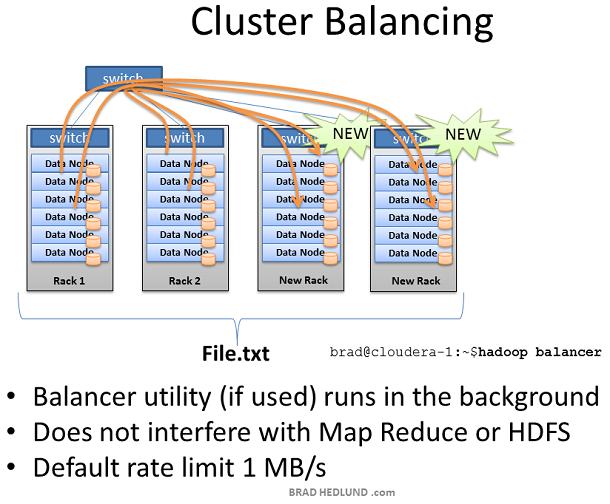
Hadoop通过在现有数据的基础上提供某种商业价值,从而在你的组织内获得成功。当人们意识到它的价值,那么你可能获得更多的资金购买更多的机架和服务器,来扩展现有的Hadoop集群。 当增加一个装满服务器的新机架到Hadoop集群中时,你可能会面临集群不平衡的局面。在上图的例子中,Rack1和Rack2是已经存在的机器,保存着文件File.txt并且正在运行Map Reduce jogs。当我们增加两个新的机架到集群中时,File.txt 数据并不会神奇的自动散布到新的机架中。 新的Data node服务器由于没有数据只能空闲着,直到Client开始保存新的数据到集群中。此外当Rack1和Rack2上的服务器都满负荷的工作,那么Job Tracker可能没有别的选择,只能把作用在File.txt上的Map task分配到这些没有数据的新服务器上,新服务器需要通过网络跨机架获取数据。这就导致更多的网络流量,更慢的处理速度。
为了处理这种情况,Hadoop包含一个时髦的工具叫做balancer Balancer查看节点可用存储的差异性,在达到特定的阀值后尝试执行balance。有很多空闲空间的新节点将被检测到,然后balancer 开始从空闲空间很少的Data node拷贝数据到这个新节点。Balancer通过控制台的命令行启动,通过控制台取消或者关闭balancer Balancer可用的网络流量是非常低的,缺省设置为1MB/s。可以通过hdfs-site.xml的df.balance.bandwidthPerSec参数来修改。 Balancer是你的集群的好管家。在你增加服务器时一定会用到它,定期(每周)运行一次也是一个好主意。Balancer使用缺省带宽可能会导致很长时间才能完成工作,比如几天或者几周。 本文是基于Training from Cloudera 的学习 以及对我的Hadoop实验环境的观测。这里讨论的内容都是基于latest stable release of Cloudera's CDH3 distribution of Hadoop 。本文并没有讨论Hadoop的新技术,比如:Hadoop on Demand(HOD)和HDFS Federation ,但是这些的确值得花时间去研究。 英文原文:http://bradhedlund.com/2011/09/10/understanding-hadoop-clusters-and-the-network/ |










 /1
/1 

