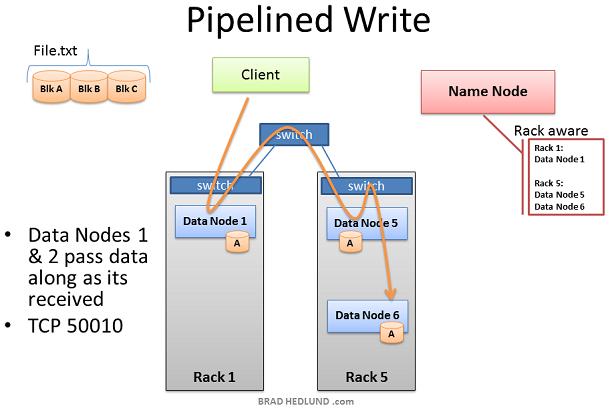
在Client写Block A之前,它要知道准备接受”Block A“ copy的Data nodes是否以及做好了准备。首先,Client选择list中的第一个节点Data Node1,打开一个TCP50010链接然后请求:“hey,准备接受一个block,这是一个Data nodes列表(2个表项),Data node5和Data node6”,请确保他们两个也准备好了“;于是Data Node1打开一个到Data node5的TCP500100连接然后说:”Hey,准备接受一个block,这是一个Data nodes列表(1个表项),Data node6”,请确保他准备好了“;Data Node5同样会问Data Node6:“Hey, 准备好接收一个block吗“ ”准备就绪“的响应通过已经创建好的TCP pipeline传回来,直到Data Node1发送一个"Ready"给Client。现在Client可以开始写入数据了。
写入数据的过程中,在涉及写操作的Data nodes之间创建一个复制pipeline。也就是说一个数据节点接收数据的同时,同时会把这份数据通过pipeline push到下一个Node中。 从上图可以看到,Rack Awareness起到了改善集群性能的做用。Data node5和Data node6在同一个机架上,因此pipeline的最后一步复制是发生在机架内,这就受益于机架内带宽以及低延迟。在Data node1, Data node5, Data node6完成block A之前,block B的操作不会开始。
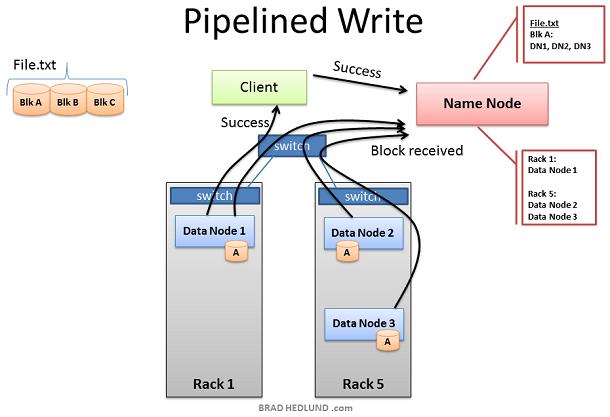
当三个Nodes成功的接收到Block A后,挥发送"Block received"报告给Name node,同时发送"Success"到pipeline中,然后关闭TCP事务。Client在接收到Success信息后,通知Name node数据块已经成功的写入。Name node更新File.txt中Block A的metadata信息(包含Name locations信息) Client现在可以开始Block B的传输了
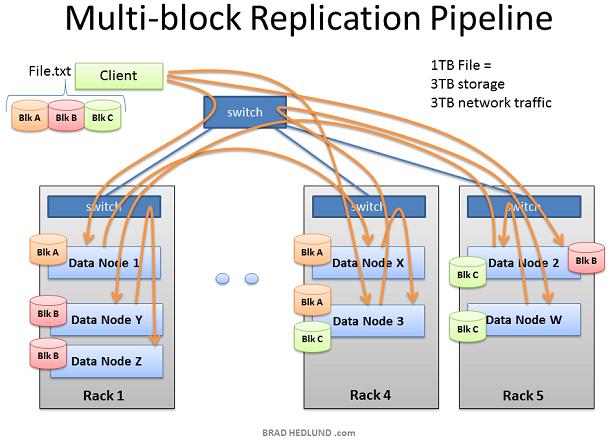
随着File.txt的块被写入,越来越多的Data nodes涉及到pipeline中,散落到机架内的热点,以及跨机架的复制 Hadoop占用了很多的网络带宽和存储空间。Hadoop专为处理大文件而生,比如TB级尺寸的文件。每一个文件在网络和存储中都被复制了三次。如果你有一个1TB的文件,那么将消耗3TB的网络带宽,同时要消耗3TB的磁盘空间存贮这个文件。
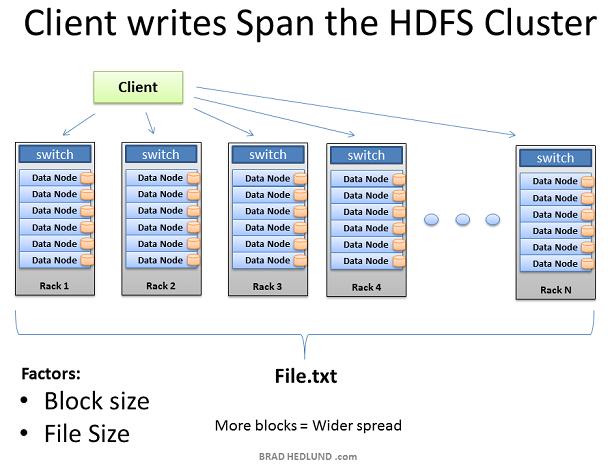
随着每块的复制pipeline的完成,文件被成功的写入集群。文件散落在集群内的机器上,每个机器保存文件的一小部分数据。组成文件的块数目越多,数据散落的机器就越多,将来更多的CPU和磁盘驱动器就能参与到并行处理中来,提供更强大更快的处理能力。这也是建造巨大集群的原动力。当机器的数变多,集群则变得wide,网络也相应的需要扩展。 扩展集群的另外一种方法是deep扩展。就是维持机器数据不便,而是增加机器的CPU处理能力和磁盘驱动器的数目。在这种情况下,需要提高网络的I/O吞吐量以适应增大的机器处理能力,因此如何让Hadoop集群运行10GB nodes称为一个重要的考虑。
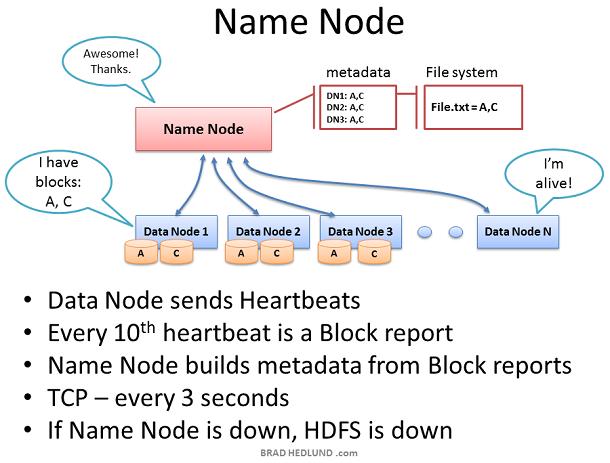
Name node保存集群内所有文件的metadata,监督Data nodes的健康以及协调数据的存取。Name node是HDFS的控制中心。它本身并不保存任何cluster data。Name node知道一个文件由哪些块组成以及这些块存放在集群内的什么地方。Name node告诉Client需要和哪些Data node交互,管理集群的存储容量,掌握Data node的健康状况,确保每一个数据块都符合系统备份策略。 Data node每3秒钟发送一个heartbeats给Name node ,二者使用TCP9000端口的TCP握手来实现heartbeats。每十个heartbeats会有一个block report,Data node告知它所保存的数据块。block report使得Namenode能够重建它的metadata以确保每个数据block有足够的copy,并且分布在不同的机架上。 Name node是Hadoop Distributed File System(HDFS)的关键部件。没有Name node,clients无法从HDFS读写数据,也无法执行Map Reduce jobs。因此Name node 最好配置为一台高冗余的企业级服务器:双电源,热插拔风扇,冗余NIC连接等。
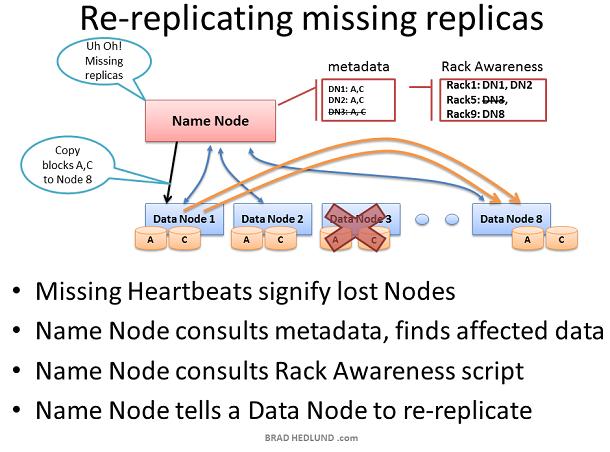
如果Name node收不到某Data node的heartbeats,那么Name node假定这个Data node死机并且Data node上的所有数据也丢失了。通过这台dead Data node的block report,Name node知道哪些block copies需要复制到其他Data nodes。Name node参考Rack Awareness数据来选择接收新copy的Data node,并遵守以下复制规则:一个机架保存两份copies,另一个机架保存第三份copy。 考虑由于机架交换机或者机架电源失败导致的整个机架Data node都失效的情况。Name node将指导集群内的剩余Data nodes开始复制失效机架上的所有数据。如果失效机架上服务器的存储容量为12TB,那么这将导致数百TB的数据在网络中传输。
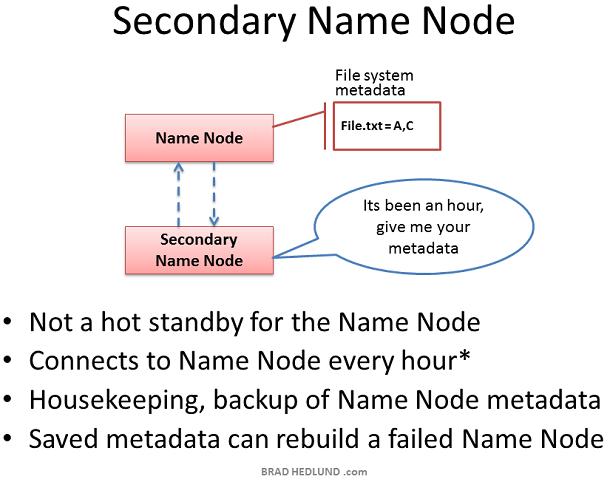
Secondary Name node是Hadoop的一种服务器角色。一个很普遍的误解是它提供了对Name node的高可用性备份,实际上不是。 Secondary Name node偶尔会连接到Name node(缺省为每小时),同步Name node in-memory metadata以及保存metadata的文件。Secondary Name node合并这些信息到一个组新的文件中,保存到本地的同时把这些文件发送回Name Node。 当Name node宕机,保存在Secondary Name node中的文件可以用来恢复Name node。在一个繁忙的集群中,系统管理员可以配置同步时间为更小的时间间隔,比如每分钟。
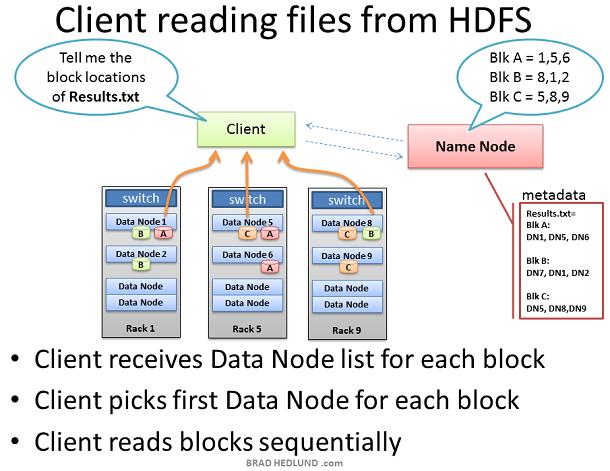
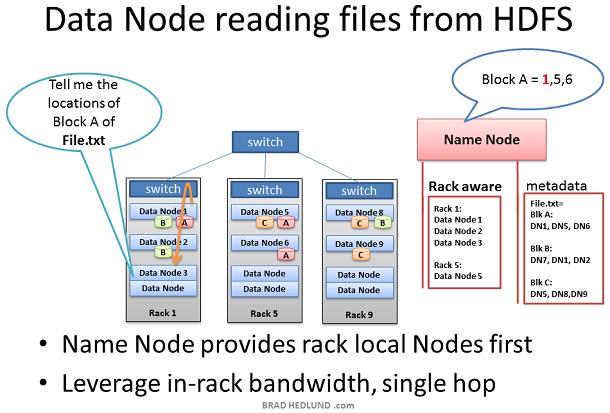
当一个Client想要从HDFS获取一个文件时,比如job的输出结果。Client首先从Name node查询文件block的位置。Name node返回一个包含所有block位置的链表,每个block位置包含全部copies所在的Data node Client选取一个数据块的Data node位置,通过TCP50010端口从这个Data node读取一块,在读取完当前块之前,Client不会处理下一块。
在某些情况下Data node daemon本身需要从HDFS读取数据块。比如Data Node被请求处理自身不存在的数据,因而它必须从网络上的其他Data node获得数据然后才能开始处理。 |










 /1
/1 

