1.3.1 数据库阶段 数据库是数据基础设施的萌芽阶段,而最早的商用数据库产品,如Oracle、DB2,均诞生于1970年代末到1980年代初。 早期的数据库应用于以OLTP(联机事务处理)场景为主,即直接承载来自业务系统、交易系统的数据存储与计算,因此这类数据库又被称之为“事务型数据库”或“交易型数据库”。在许多情况下,人们也将它等同于狭义的数据库。 业务场景 该阶段的企业缺乏成熟、可落地、面向一线业务人员的数字化场景,核心痛点是为企业管理层解决宏观层面的经营决策问题。 因此,该阶段的数据查询维度、数字化展现形式都比较单一,主要是基于固定的若干张数据表,生成面向管理层的固定报表、可视化大屏等。 组织架构 该阶段的企业普遍缺乏专业的数字化人才,也缺乏成熟的数字化组织架构与文化,主要由IT人员承担面向管理层的数字化场景的落地。 数据基础设施的技术架构 该阶段的数据基础设施,尚未完全从业务系统的交易数据库中分离出来。对数据分析需求,企业一般基于交易型数据库单独建设一套用于分析查询的历史数据库,汇集来自不同交易数据库的原始数据。在少部分数据分析场景下,企业还会直接用交易数据库进行支持。 交易型数据库的软硬件架构都采取共享存储架构,即计算节点能够访问到任意的存储节点,同时需要基于专有物理硬件,由此保证对性能的良好优化。 数据基础设施的功能及性能特点
1.3.2 数据仓库阶段1990年代后,尤其是随着E.F.Codd于1993年正式提出联机分析处理(OLAP)的概念,数据基础设施开始进入“数据仓库”时代。 业务场景 该阶段的企业开始具备一定的数字化意识,数据分析的需求开始从管理层下沉到业务部门,核心痛点是为一线业务人员的解决业务决策问题。 由于OLAP的数据查询维度更加复杂,查询频次更高,企业开始将承载OLAP工作负载的数据库与业务系统的交易数据库进行分离,从而避免OLAP对核心交易造成干扰。因此,专用于OLAP的分析型数据库诞生,并逐步从交易型数据库中分离出来,也因此获得了“数据仓库”这一更加形象的别称。 该阶段的数字化展现形式,仍然以传统报表和可视化大屏为主,因此为了支撑业务部门的数据分析需求,需要具备专业的数据分析人员响应需求,并提供技术支持。 但是,为了满足业务人员需要,企业需要存储更多的历史数据,常常需要对数据仓库进行扩容,而Oracle、DB2等交易型数据库扩展性较差,难以满足扩容需求。因此,基于MPP无共享架构的数据库逐步进入人们视野。 组织架构 在组织架构层面,该阶段的企业大多仍然由IT部门来支撑数字化,业务部门、IT部门均缺少数字化人才。因此,其IT组织架构尽管能够支撑一定频次的业务需求,但对于紧迫需求仍然难以充分响应。 数据基础设施的技术架构 数据仓库的软硬件架构经历了较为漫长的发展历程。 1980年代,Teradata首次推出了采取MPP无共享存储架构的数据库,其主要特点是基于大规模并行处理(MPP)架构,即在每个计算节点都有自己独有的存储节点,数据并均匀打散到所有节点存储,并将多个并行任务分散到不同的节点上执行。此外,Teradata继续采用了类似早期Oracle、DB2等数据库的专有物理硬件。到1990年代之后,MPP数据库被越来越多的应用到数据仓库的构建之中。 到2006年前后,Greenplum、Vertica等支持x86通用服务器的MPP数据库出现,降低了数据仓库的建设和扩容成本。 数据基础设施的功能及性能特点
1.3.3 大数据平台阶段2005年后,由于互联网、移动互联网的逐步普及,业务系统的终端用户量的爆发式增长,企业内沉淀的数据量同样呈现爆发式增长,数据基础设施开始进入“大数据平台”阶段。 业务场景 在互联网、移动互联网技术的推动下,金融、电商、社交娱乐等领域的企业开始越来越多地触及终端用户的线上数据。这些数据具有多样、多维度、大规模的特点。 首先,数据类型十分多样,包括结构化数据(关系型数据库中的表)、半结构化数据(如CSV、XML、日志、JSON)、非结构化数据(电子邮件、文档)、二进制数据(图形、音频、视频)等。其次,数据维度更多,包含了用户的各类行为数据。此外,存储的数据量也从过去的GB、TB级别,进一步提升高PB、EB级别。 该阶段的数字化展现形式更加多样,除了传统报表、可视化大屏,具备自助式分析能力的敏捷BI工具逐步普及。这使得在部分场景下,业务人员能够自行进行数据探索与分析,而不再需要IT人员、数据分析师随时进行技术支持。 但是,MPP数据仓库的扩展规模仅能到数百节点,难以进一步扩容,而且不支持非结构化、半结构化数据,逐渐难以满足企业需求。在这样的背景下,以Hadoop为代表的大数据技术逐步成为数据基础设施的核心技术之一。 组织架构 该阶段的企业,普遍开始拥有具备业务理解能力和数据分析能力的数字化人才,但人才往往分散在各业务线,或归并在IT部门,缺乏统一的数字化组织架构,以及对数字化的整体推动能力。 数据基础设施的技术架构 以Hadoop为代表的大数据技术为企业统一采集、存储与处理各类等多种类型数据提供了技术可能性,“数据湖”架构的理念也由此诞生,而许多企业又将“数据湖”称之为“大数据平台”。 基于Hadoop生态的大数据平台,需要兼容前一阶段建设的MPP数据仓库,同时提供基于SQL-on-Hadoop(如Hive、SparkSQL)的数据仓库,以及包括NoSQL数据库(如HBase)、流处理、批处理、分布式存储(如HDFS)在内的大数据套件。 与MPP数据仓库的共享存储架构不同,SQL-on-Hadoop数据仓库基于HDFS等分布式、软件定义的存储,在软件层面实现了存储节点与计算节点的相互独立,因此可以实现计算、存储独立扩展。 数据基础设施的功能及性能特点(仅针对SQL-on-Hadoop数据仓库)
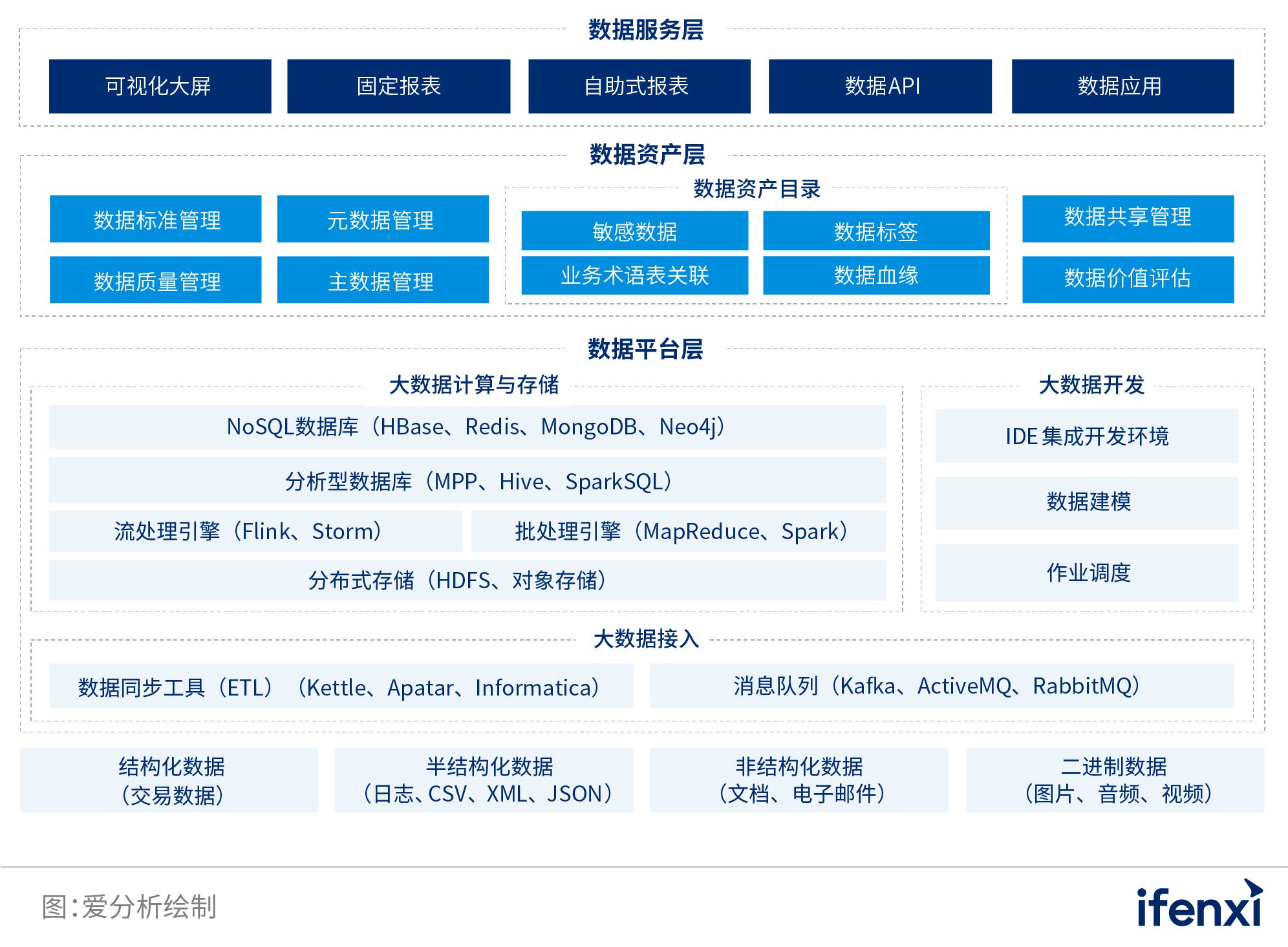
1.3.4 云数据平台阶段2015年后,企业上云已经成为普遍共识,同时企业各业务部门对大数据分析的需求更加普遍化、敏捷化、个性化、场景化,数据的业务价值也由辅助决策转变为推动创新。在这一背景下,数据基础设施开始进入“云数据平台”阶段。 业务场景 该阶段的企业,其数字化场景更加广泛且普遍,而且产生了大量的跨部门、跨业务线,甚至跨分支机构、跨组织、跨地域的数据共享与联动分析。同时,孵化于企业原有体系内,但又需要由数据来驱动迭代优化的创新业务层出不穷。 因此,企业数字化转型思路需要从过去的单个场景突破,转变为全集团、跨组织、跨地域的数据共享与资产化管理,以及全场景数据赋能。 组织架构 为了推动集团层面的业务、数据共享,加速业务的敏捷创新,企业需要在组织架构层面对数字化人才、数据基础设施的管理和运营团队进行统筹规划。 比如,以阿里巴巴、腾讯为代表的互联网巨头都先后提出了“中台战略”,成立中台部门对数字化战略进行统筹。为了推动数据的跨部门复用与共享, “数据中台”的概念也被同时提出。 数据基础设施的技术架构 然而,“数据中台”概念的局限性在于并未改变数据基础设施的底层技术架构,而是沿用了大数据平台阶段的技术架构,并保留了传统技术路线带来的弊端。 对此,云数据平台采用了计算与存储分离、虚拟计算集群等新型技术架构,对象存储等云原生技术对数据平台进行了深度优化。 数据基础设施的功能特点 基于云原生、计算存储分离、虚拟计算集群等新型技术架构,云数据平台实现计算、存储节点独立扩展,突破了基于MPP、SQL-on-Hadoop技术的大数据平台在扩展性、灵活性方面的局限。 此外,云数据平台还克服了SQL-on-Hadoop数据库在SQL标准、ACID特性等方面的不足,可以支持数字化应用从传统共享存储数据仓库、MPP数仓向云数据平台的平滑迁移。 最后,大数据平台的基础上,云数据平台吸纳了来自“数据中台”理念的数据资产层与数据服务层,从而形成“数据平台-数据资产-数据服务”的三层架构。 图 5: 云数据平台“平台-资产-服务”三层架构
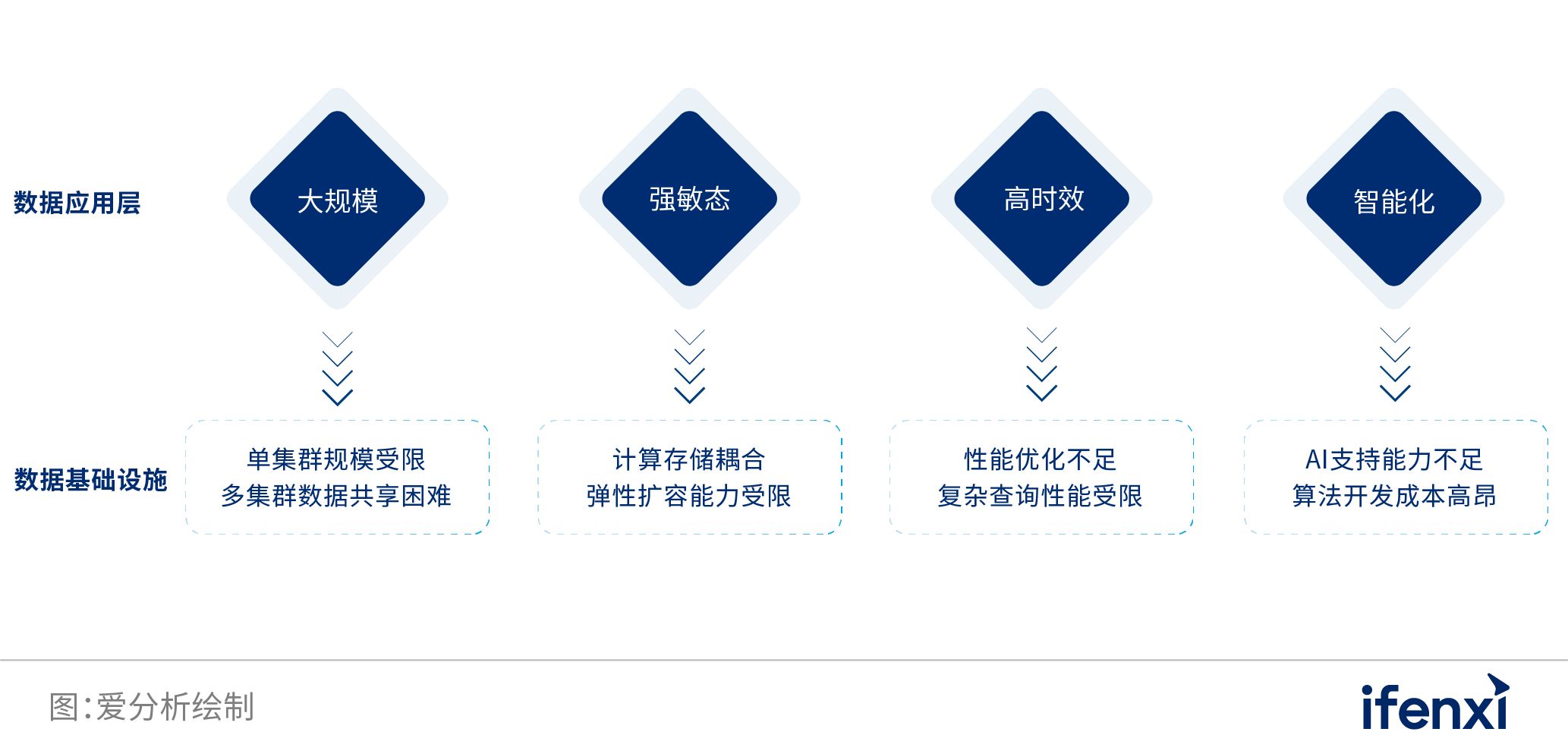
数据基础设施的性能特点 相比于大数据平台,云数据平台摆脱了以Hadoop为核心的技术体系的影响,克服了其在性能优化和并发等方面的缺陷,对云平台进行了原生优化,尤其是在分析型云数据仓库方面,可以支持计算与存储分离,弹性可扩展,支持数千节点规模集群,虚拟计算集群,湖仓一体,并对性能做了深度优化,从而大幅度提升面向多张表、批量数据、复杂表关联的复杂查询性能。 2. 企业数字化深入推进,云数据平台价值显现尽管数据基础设施经历了漫长的演进历程,但从数据库、数据仓库到大数据平台阶段,数据基础设施在扩展能力、弹性能力、查询性能、易迁移性等方面,始终受到技术路线繁杂、遗留问题重重的MPP、SQL-on-Hadoop等上一代数据仓库技术的制约。 同时,企业数字化实践的主战场,已经从过去的互联网、创新型企业,全面转到以集团型、多分支企业为代表的大中型传统企业,数字化需求的深度、广度出现全面提升。 然而,时下的“数据中台”解决方案,本质上只是在大数据平台的基础上,融合了数据资产化与数据服务化的管理能力,并没有对大数据平台的原有技术路线进行革命性升级。 因此,数据基础设施需要对技术进行彻底变革,变得更加统一与强大,而新一代数据基础设施——“云数据平台”的出现,则预示着数据基础设施的未来变革方向。 2.1 四大新挑战困扰企业数字化转型金融、能源、制造、零售等行业内,存在着许多体量庞大、组织架构复杂的集团型、多分支企业。然而,这类企业在推进数字化转型过程中,数字化应用逐步表现出了“大规模”、“强敏态”、“高时效”、“智能化”等四大新特征,对数据基础设施提出了相应的四大挑战,如下图所示。 图 6: 数据基础设施面临的四大挑战
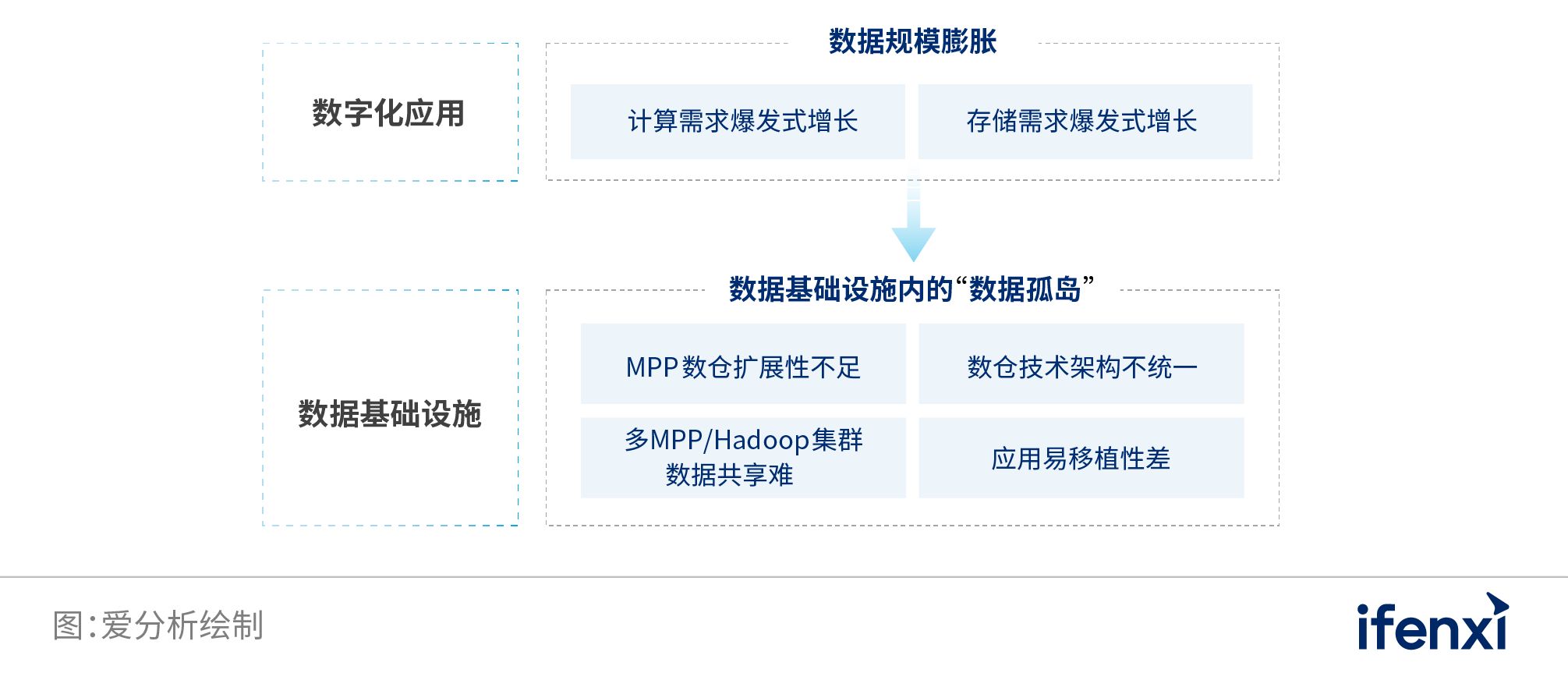
2.1.1 数据规模膨胀,数据基础设施产生新“数据孤岛”金融、电力、电信等行业内企业,普遍存在业务系统众多、交易次数巨大、交易额度巨大、数据积累量巨大等特征。据公开数据显示,2019年全国银行卡交易总次数为3219.89亿笔,日均8.82亿笔,交易总金额886.39万亿元,日均2.43万亿元。 因此,企业内的数字化应用对数据基础设施的计算并发量、存储上限的要求越来越高,数据基础设施的节点规模出现了急剧膨胀。比如,某国有大行需要分析数十PB级交易数据,需要3000以上的数仓节点才能满足存储需求。 图 7: 数据规模膨胀对数据基础设施的挑战
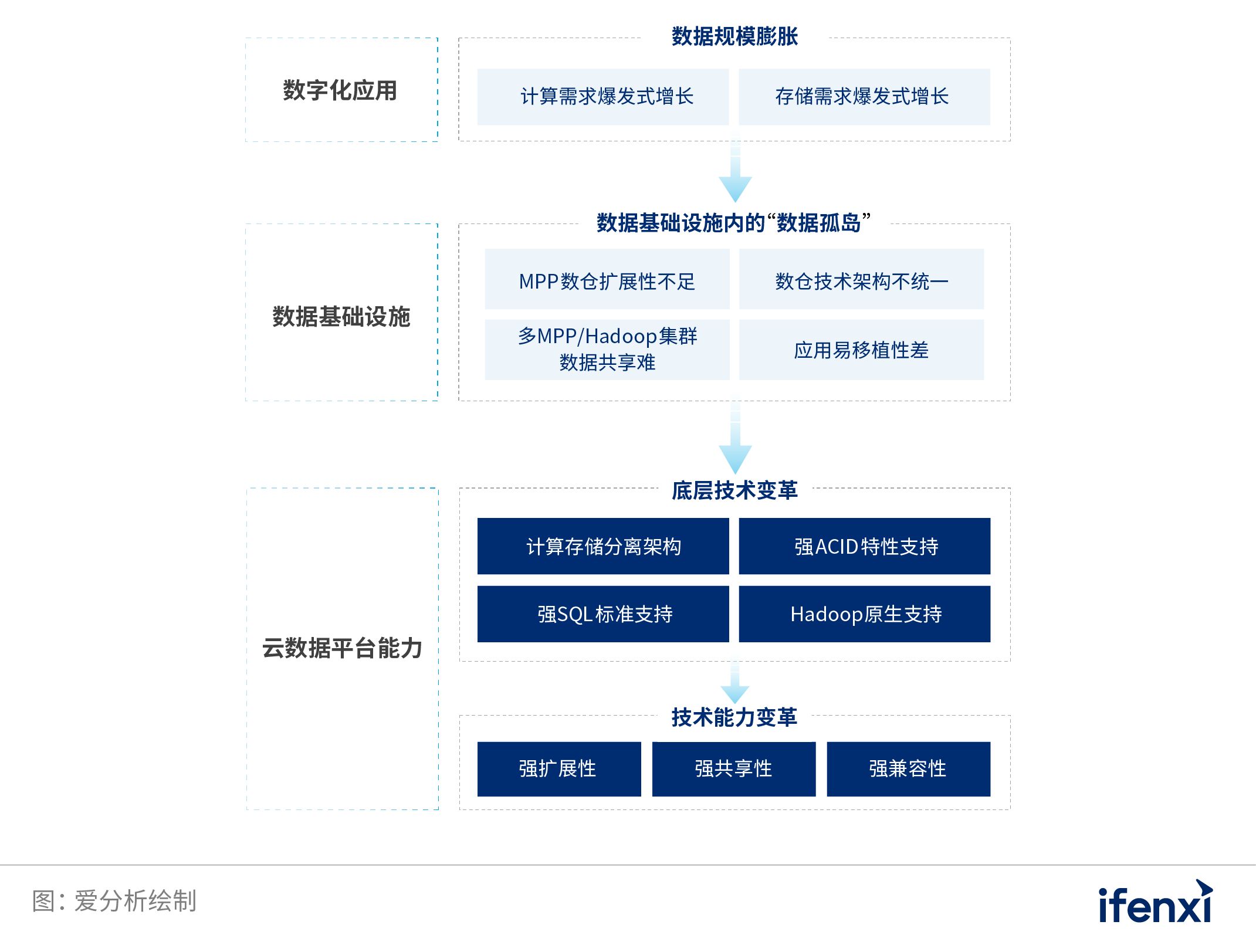
在这样的背景下,两方面因素共同导致了数据基础设施内的“数据孤岛”产生,进一步拉高了企业的数据运维管理成本。 传统交易型数据库与MPP数仓的节点规模限制 目前,MPP凭借对SQL标准、ACID特性的良好支持,仍然是大型企业的核心数字化应用的主流选择。此外,许多企业还在采用Oracle、DB2等传统的交易型数据库来支撑数据分析业务。 面对膨胀的数字化应用规模,企业内的数据基础设施一旦达到可扩展的节点上限,必须采用多集群部署方式,即通过应用级的多集群划分来支撑更多的应用带来的并发计算,通过多集群间的数据分散存储来支撑更高规模的数据存储。 但是,传统交易型数据库、MPP数据仓库的可扩展节点上限仅在十几到上百节点,在许多数字化较为领先的大型企业内,节点需求已经很容易突破上限,因而同时部署多个MPP集群,已经成为大型企业数字化的必须。 比如,某国有大行需要分析10PB级交易数据,需要3000以上的数仓节点才能满足存储需求,因此只能建立40个MPP集群。但是,多集群间的数据共享十分困难,该行只能对部分数据在多个集群进行多份冗余存储,导致最终的实际数据存储量高达几十PB,集群之间数据很容易产生不一致,给该行造成了极大的运维负担。 由此可见,尽管数据基础设施的出现与发展始终是为了实现数据共享利用,消除交易型数据库之间的“数据孤岛”,但是多集群的现状,事实上在数据基础设施内部制造了新的“数据孤岛”。 不同技术架构的数据仓库间的应用易移植性问题 与传统交易型数据库、MPP数仓不同,Hive、SparkSQL等SQL-on-Hadoop数仓具备上千节点规模的扩展能力,但其缺陷在于对SQL标准、ACID特性的支持能力不足,性能比MPP差多倍,并发支持有限,因此许多大型企业倾向于将更多地应用在边缘业务的数字化场景中,与MPP数仓并行使用,共同构建数据基础设施。 然而,传统交易型数据库、MPP数仓、SQL-on-Hadoop数仓在计算存储架构方面的差异,以及在SQL标准、ACID特性上的不兼容,意味着双方之间的数据迁移和共享十分困难。 但是,未来大型企业的数字化,往往不再是过去由单个部门、单条业务线驱动的数字化,而是越来越多地由战略层面进行统筹规划,全部门、全业务线协同推进的数字化。在这种背景下,大型企业常常需要将过去独立建设的数字化应用进行迁移,以同一套数据基础设施支撑上层各个业务线的数字化应用,不但实现了管理的统一,还可提升其扩展能力。 因此,在将遗留的数字化应用在不同技术架构进行迁移过程中,往往需要进行大量的代码重构,移植成本较高,难以实现平滑迁移。 例如,某电网系统内分公司搭建了基于Hive的大数据测试环境,但是拥有更多计算节点的Hive大数据分析性能对比Oracle几乎没有提升,且原有基于Oracle的众多应用系统向Hive迁移时,由于Hive不支持存储过程等Oracle很多功能,需要改写的代码量巨大。 因此,大型企业在数字化过程中,亟需探索一套通过“大一统”方式来建设数据基础设施的解决方案,消除数据基础设施内的“数据孤岛”现象。 为了应对这些挑战,新一代数据基础设施——“云数据平台”应具备以下能力:
图 8: 云数据平台应对数据规模膨胀挑战
|










 /1
/1 

