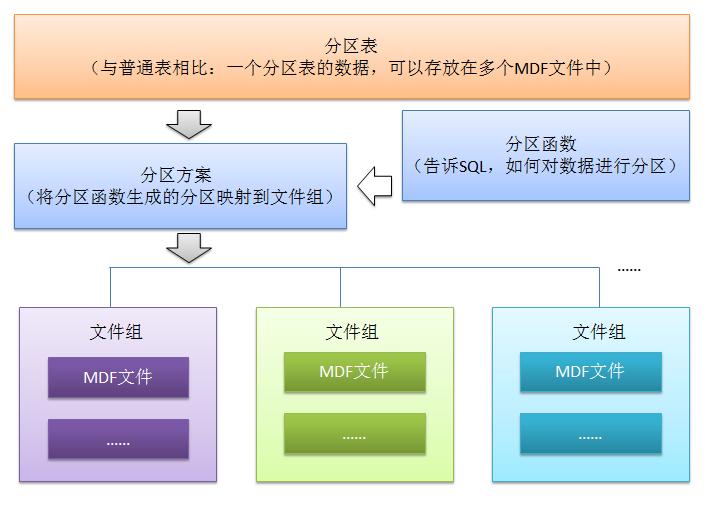
大数据处理是一个头疼的问题,特别当达不到专业DBA的技术水准时,对一些数据库方面的问题感到无奈。所以还是有必要了解一些数据库方面的技巧,当然,每个人都有自己的数据库方面的技巧,只是八仙过海,所用的武功不同而已。我把我最常用的几种方式总结来与大家分享,大家还有更多的数据库设计和优化的技巧,尽量的追加到评论中,有时一篇完整的博客评论比主题更为精彩。 方法1:采用表分区技术。 第一次听说表分区,是以前的一个oracle培训。oracle既然有表分区,就想到mssql是否有表的分区,当时我回家就google了一把,资料还是有的,在这我儿只是再作一次推广,让更多的人了解和运用这些技术。 表分区,就是将一个数据量比较大的表,用某种方法把数据从物理上分成若干个小表来存储,从逻辑来看还是一个大表。首先来个结构图:
上图虽然不能很清晰的表达表分区的执行过程,但是可以看出表分区要用到那些对象,比如数据文件,文件组,分区方案,分区函数等。 我们以一个用户表(TestUser)为例,假设这个表准备用来存储中国部分公民的数据,每条数据记录着每个人所属的省份(Area),以及每个人的姓名(UserName),如下图所示。当数据量达到1千万的时候,查询就比较慢了,这时候的数据优化就迫在眉睫。
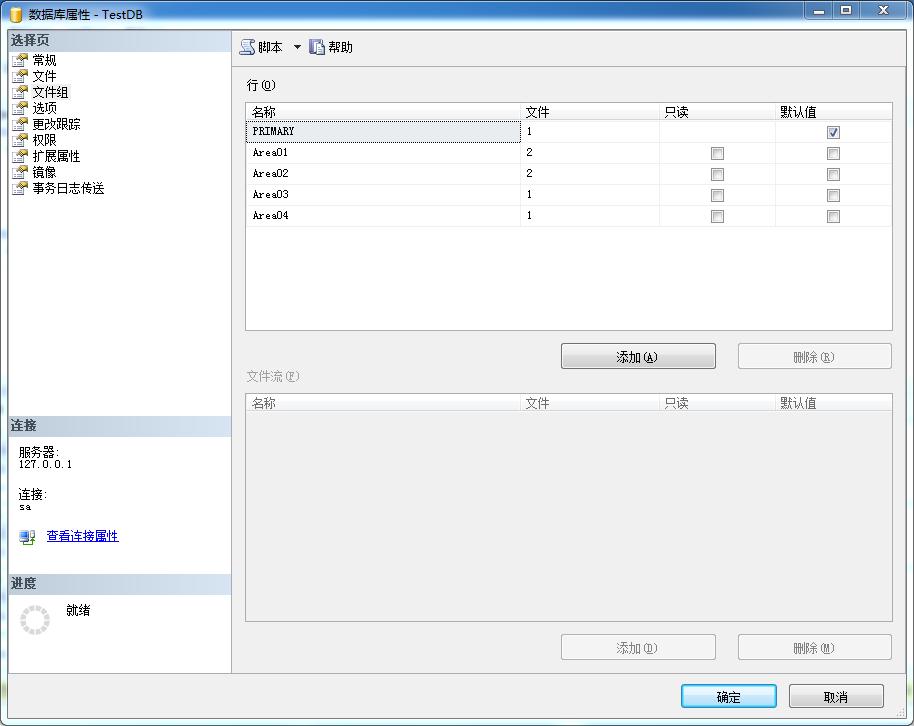
在优化之前,根据数据的结构,读写操作等,肯定会提出若干个解决方案。在这儿就以分区表的方案来优化数据库的查询,这儿以区域来分别存储数据,比如广东的公民存放在AreaFile01.MDF文件中,湖南的公民存放在AreaFile02.MDF的文件中,四川的公民存放在 AreaFile03.MDF的文件中,以此类推其它省份,为了实现这个功能我们就得做分区方案。在做分区方案时,首先要搞清楚分区方案要涉及到的四个对象:文件组,文件,分区函数,分区方案。 a:文件组,用来组织数据文件(.MDF)的一个虚拟名称,一个文件组可以添加多个数据文件(.MDF)。打开SQL管理器,找到具体的数据库,然后右键【属性】,进入到【文件组】选项卡,添加Area01,Area02,Area03,Area04四个文件组。如图:
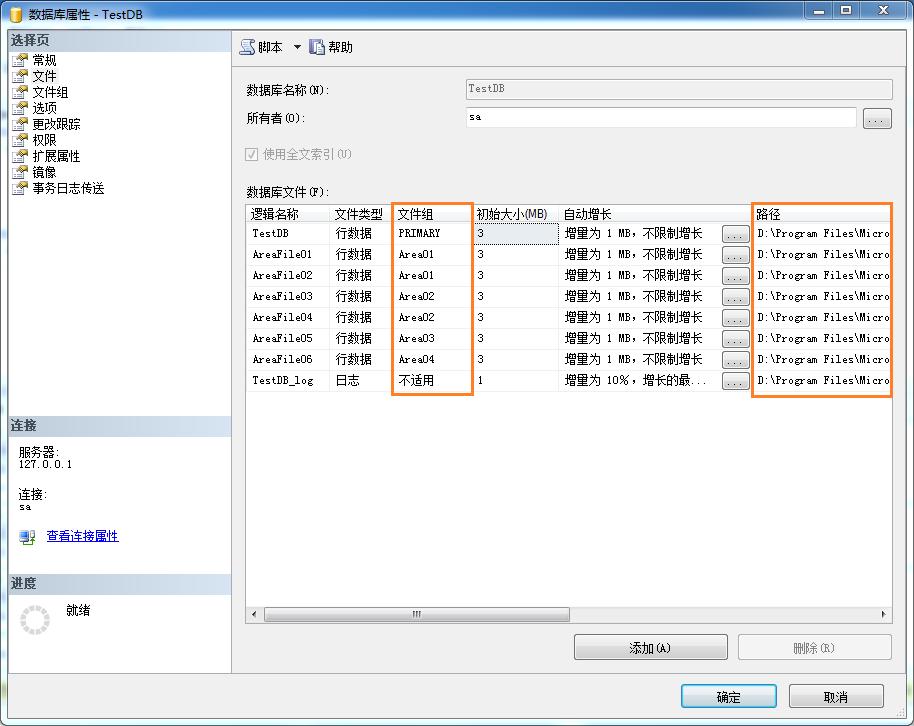
b:然后选择中【文件】选项卡,添加 AreaFile01,AreaFile02,AreaFile03,AreaFile04,AreaFile05,AreaFile06六个数据文件(.MDF),然后指定每个文件属于那个文件组(一个文件组可以存储多个数据文件),以及这个文件的物理路径。在这儿大家已经看明白了,这些数据文件,就是物理上来分割一个数据表的数据的。也就是说一个表的数据有可能存储在AreaFile01中,也有可能存储在AreaFile02中,只要用某种方法来指定他们的存储规则就行了。
c:分区函数,就是指定数据的存储规则。就是告诉SQL,把新增的数据如何分区。创建一个分区函数,可以用下边的SQL语句来实现。
d:辛苦的创建了文件,又为其指定文件组,还建一个分区函数,目的只有一个,就是为了创建一个分区方案。分区方案可以用以下代码来创建。
经过紧张的四步操作,一个分区方案就呈现在我们的眼前了。接下来的事,就是我们要怎样来消费这个分区方案。 首先我们创建一人普通的表,然后给这个表指定一个分区方案。如下代码。
为了能看到效果,再插入一些数据。
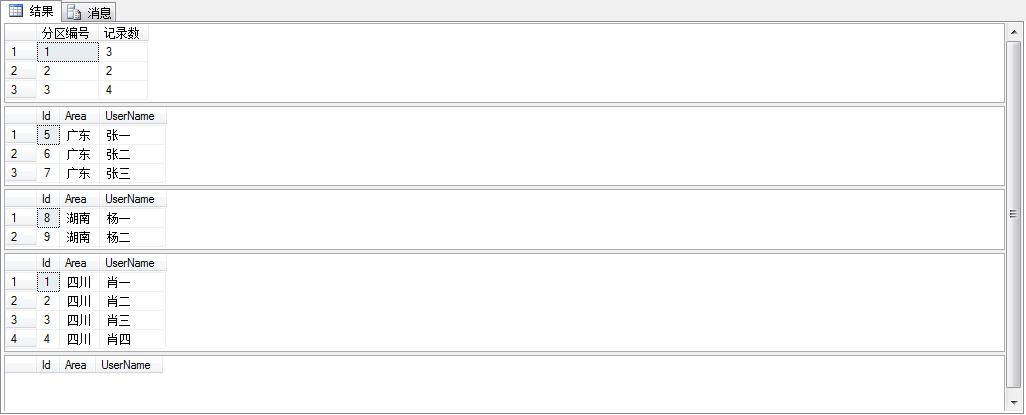
查询所有的数据,可以用select * from TestUser; 按分区查询:就用如下方法:
效果图:
你们看我一个简单的表的分区是不是就已经完成了。呵呵,当然在实际应用中,仅仅掌握这点是不够的,比如在原分区方案上添加一个分区,删除一个分区。 |











 /1
/1 

