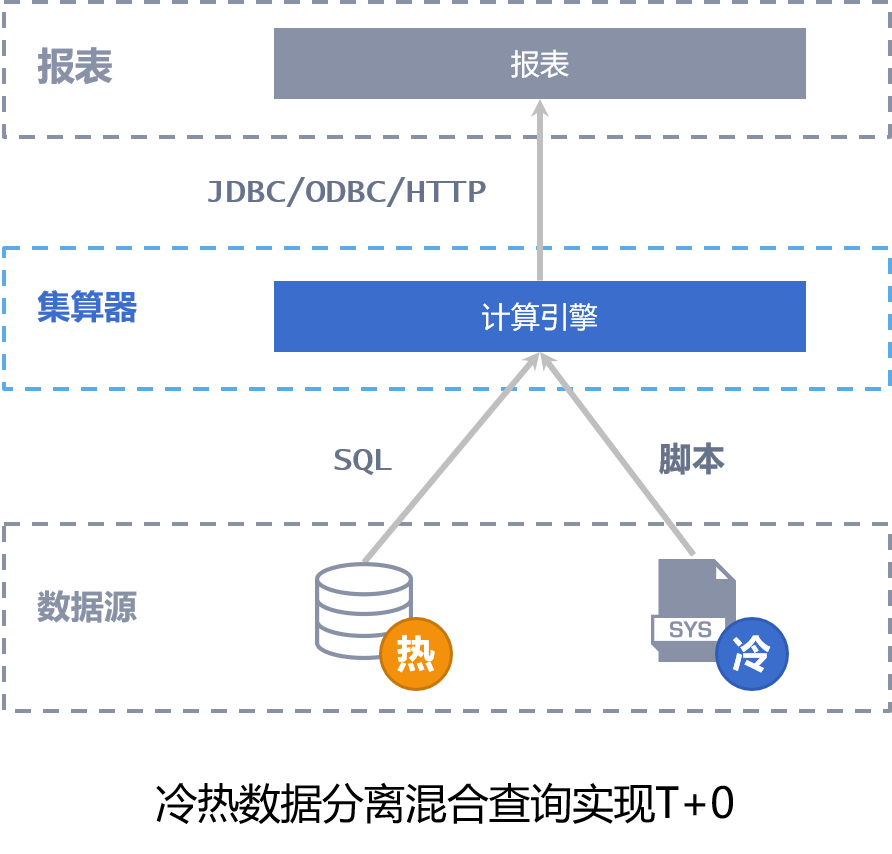
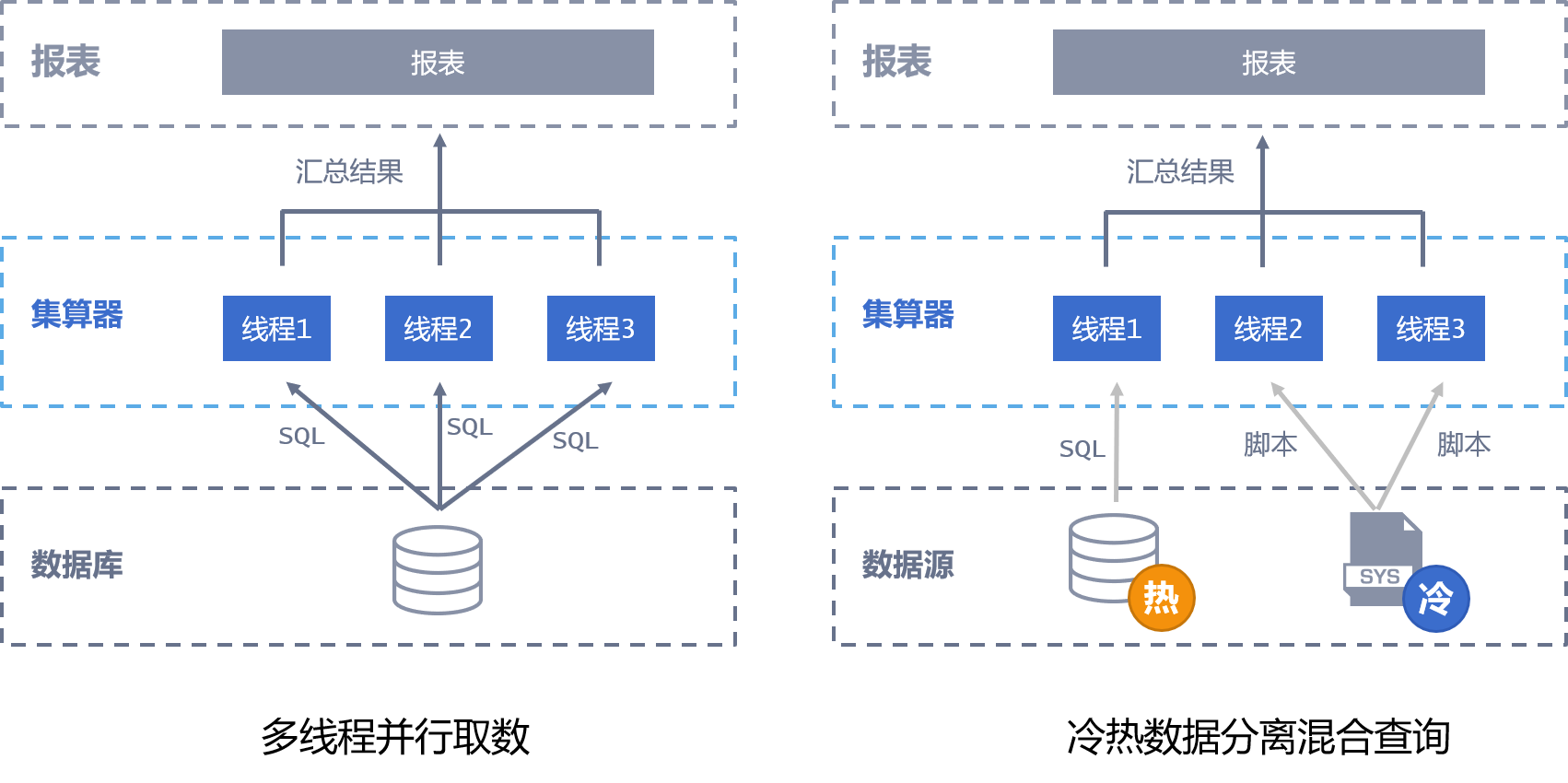
11
1
292
中级会员
举报
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
版权所有: Discuz! © 2001-2013 大数据.
GMT+8, 2024-4-25 17:59 , Processed in 0.179891 second(s), 24 queries .



 发表于 2018-10-16 09:34:28
发表于 2018-10-16 09:34:28