|
|
一、问题描述 键值查询是很常见的查询场景,在数据表上建有索引后,即使表中数据记录数巨大(几亿甚至几十亿行),用键值查询出单条记录也会很快,因为建立索引后的复杂度只有 logN(以 2 为底)次, 10 亿行数据也只要比较 30 次(10 亿约等于 2^30),在现代计算机上也只需要数十毫秒而已。
不过,如果需要查询的键值很多,比如多达几千甚至几万的时候,如果每次都独立查找,那读取和比较也会累积到几万甚至几十万次,时间延迟由此也会涨到几十分钟甚至小时级别,这时候简单地使用数据库索引对于用户体验必然是难以容忍的了。
二、场景举例 下面我们要介绍的集算器组表功能,基于高性能索引和批量键值查找,可以有效地应对这种场景。我们会按照以下几种顺序逐步深入讨论:
1)单字段键
2)多字段键 3)多线程查询 4)数据追加的处理 需要说明的,本文只研讨单机的情况,后续还有文章会继续深入讨论基于集群的方案。
2.1 单字段键 我们以下表这种比较典型的数据结构为例:
字段名称
| 类型
| 是否主键
| 说明
| id
| long
| 是
| 从 1 开始自增
| data
| string
|
| 需要获取的数据
|
2.1.1创建组表 首先我们创建一个组表,把源数据导入组表:
| A
| 1
| =file("single.ctx")
| 2
| =A1.create(#id,data)
| 3
| =file("single_source.txt")
| 4
| =A3.cursor@t()
| 5
| =A2.append(A4)
|
A1:建立并打开指定文件对象,这里的 single.ctx 是将要创建的组表文件,扩展名用 ctx。关于组表的详细定义和使用方法可以参考集算器教程。
A2:创建组表的数据结构为(id,data)。其中,# 开头的字段称为维字段,组表将假定数据按该字段有序,也就是组表 A2 将对键字段 id 有序。组表默认使用列存方式。
A3:假定源数据以文本方式存储,A3 打开数据文件。这个 txt 文件的数据表头以及前几行部分数据如下图所示。当然,源数据也可以来自数据库等其它类型的数据源。

A4:针对源数据生成游标。其中 @t 选项指明文件中第一行记录是字段名。
A5:将游标 A4 中的记录追加写入组表。
上面的脚本假定主键 id 在原始数据中已经是有序的了,如果实际情况的主键并非有序,那就需要先将主键排序后再建为组表。这时可以使用cs.sortx()函数排序,具体方法详见函数参考。
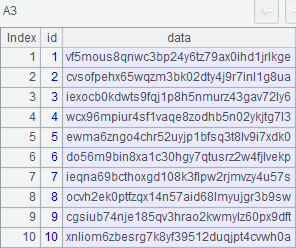
在集算器的设计器中,通过三行代码,可以直观看到其中前十条数据,代码和截图如下所示:
| A
| 1
| =file("single.ctx")
| 2
| =A1.create()
| 3
| =A2.cursor().fetch(10)
|
A1:打开指定文件名的组表文件对象。
A2:f.create(),函数中无参数时则直接打开组表。
A3:使用游标访问 A2 中的前十条数据,如下图。
2.1.2 创建索引 接下来,我们为组表文件建立索引,以提升检索性能:
| A
| 1
| =file("single.ctx")
| 2
| =A1.create()
| 3
| =A2.index(id_idx;id;data)
|
A1:打开指定文件名的组表文件对象。
A2:使用无参数的 create 函数打开组表。
A3:建立索引。在函数 T.index() 中,参数 id_idx 是索引名称,id 是维,data 是数据列。一般情况下,建索引并不需要使用数据列,在用索引查找时会到原数据表中再去找数据。不过,本例在建立索引时将数据列也包含进了索引,这样查找时就不再引用数据列了,虽然占用的空间会大一些,但是查找的也会更快一些。
按维字段建索引时会利用组表已经有序的特点不再排序。如果开始建组表时没有使用 #,那么这时建索引时就会重新排序。
2.1.3查询 使用主、子程序调用的方式来完成查询:
查询子程序脚本 search.dfx:
| A
| 1
| =file("single.ctx")
| 2
| =A1.create()
| 3
| =keys
| 4
| =A2.icursor(;A3.contain(id),id_idx)
| 5
| >file("result.txt").export@t(A4)
|
A3:keys 是参数,由下面的主程序在调用时传递。
A4:在组表的 icursor()这个函数中,使用索引 id_idx,以条件 A3.contain(id) 来过滤组表。集算器会自动识别出 A3.contain(id) 这个条件可以使用索引,并会自动将 A3 的内容排序后从前向后查找。
A5:将 A4 中查询出的结果导出至 result.txt。这里 @t 选项指定导出时将输出字段名。
主程序脚本:
| A
| 1
| =file("keys.txt").import@i()
| 2
| =call("search.dfx",A1)
|
A1:从keys.txt获取查询键值序列,因为只有一列结果,可以使用 @i 选项,将结果返回成序列:
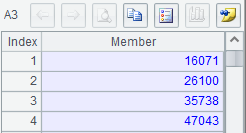
这个序列就是需要进行查询的随机键值集。例子中使用 keys.txt 来预先存好随机的键值,实际应用中,也可以用其他数据源来存储。
A2:调用子程序 serach.dfx,把 A1 获得的键值集作为参数传递给子程序。
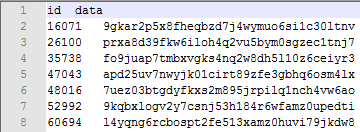
下面就是结果文件 result.txt 中的部分内容:
另外,我们还可以将集算器嵌入到 Java 应用程序中,从而为 Java 应用提供灵活、简便的数据查询能力。嵌入时可以像用 JDBC 访问数据库那样访问集算器脚本。具体的写法可以参阅教程《被 JAVA 调用》一节。
本例的单字段键查询示例,在数据结构上较为简单。其中查询的键值字段为 id,需要获取的数据为单列的 data,如果还有其它列,例如:
字段名称
| 类型
| 是否主键
| 说明
| id
| Long
| 是
| 从 1 开始自增
| data1
| String
|
| 需要获取的数据 1
| data2
| Int
|
| 需要获取的数据 2
| ……
| ……
|
| ……
| dataN
| ……
|
| 需要获取的数据 N
|
那么在建立索引步骤时,就应该包含多个数据列字段,数据列参数的写法如下所示:
| A
| 1
| =file("single.ctx")
| 2
| =A1.create()
| 3
| =A2.index(id_idx;id;data1,data2,…,dataN)
|
在接下来要讨论的多字段键情况中,建索引时需要建立多个索引字段,对应参数部分也有类似的写法:index(id_idx;id1,id2,…,idN;data1,data2,…,dataN)。
2.2多字段键 多字段健指的是联合主键的情况,例如:
字段名称
| 类型
| 是否主键
| 说明
| type
| string
|
| 可枚举
| Id
| long
|
| 每种枚举类型的 id 都从 1 开始自增
| data
| string
|
| 需要获取的数据
|
其中 type 和 id 两个字段作为联合主键确定一条记录。
2.2.1 方法一(通用方法) 2.2.1.1 创建组表
| A
| 1
| =file("multi.ctx")
| 2
| =A1.create(#type,#id,data)
| 3
| =file("multi_source.txt")
| 4
| =A3.cursor@t()
| 5
| =A2.append(A4)
|
本例中 A2 需要指定两个维,type和 id,代码其它部分与单字段键一致。
2.2.1.2 创建索引
| A
| 1
| =file("multi.ctx")
| 2
| =A1.create()
| 3
| =A2.index(type_id_idx;type,id;data)
|
由于本例中有两个维,建立索引时需要包含 type 和 id 两个维,如 A3 所示。
2.2.1.3 查询
| A
| 1
| =file("multi.ctx")
| 2
| =A1.create()
| 3
| =[["type_a",55],["type_b",66]]
| 4
| =A2.icursor(;A3.contain([type,id]),type_id_idx)
| 5
| >file("result.txt").export@t(A4)
|
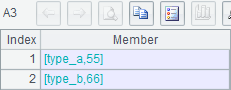
A3准备了两条数据,是由 type 和 id 构成的二元组,作为查找的建值集,结构如下图所示:

A4:A3.contain([type,id]),基于二元组的序列进行数据的筛选,所以需要将 contain 函数中的参数也变为二元组。
最终导出的结果文件内容如下:
2.2.2 方法二(合并主键) 虽然多字段键可以直接使用,但是涉及到集合的存储和比较都要慢一些。为了获取高性能,更常用的办法是把多字段键拼成单字段键。
观察本例数据结构,虽然 type 是个串,但却是可枚举的,因此可以将 type 数字化后,与 id 合并为一个新的主键字段。而 long 类型最大值为 2^63-1,完全可以容纳 id 和 type 数字化后的合并结果。我们把 type 和 id 合并后的新主键叫做 nid,可以按数据的规模,确定 nid 中分别用几位代表 type 和 id。
举例来说,id 的范围是 9 位数,type 的枚举个数用 3 位数表示就够了。因此对于 nid 而言,需要 13 位(为了避免前几位是 0,看上去不整齐,我们把第一位数字设为 1)。这样就可以把联合主键变成单字段的唯一主键,去掉第一位后的 12 位数,前 3 位代表数字化后的 type,后 9 位就是原来的 id。
代码如下:
| A
| 1
| =["type_a",……,"type_z","type_1",……,"type_9","type_0"]
| 2
| =A1.new(#:tid,~:type)
| 3
| =file("multi_source.txt")
| 4
| =A3.cursor@t()
| 5
| =A4.switch(type,A2:type)
| 6
| =A4.new(1000000000000+type.tid*long(1000000000)+id:nid,data)
| 7
| =A4.skip(99999995)
| 8
| =A4.fetch(10)
|
A1:type 的枚举值组成的序列。在实际情况中,枚举列表可能来自文件或者数据库数据源。。
A2:给枚举值序列中每个 type 一个 tid。为后续的数字化主键合并做准备。
A3~A6:从 multi_source.txt 文件中获取数据,并按照 A2 中的对应关系,把 type 列的枚举串变成数字,然后将 type 和 id 进行合并后,生成新的主键 nid。
A7~A8:查看一下合并逐渐后的数据情况,跳过游标 A4 的前 99999995 条记录后,取 10 条记录,结果如下:
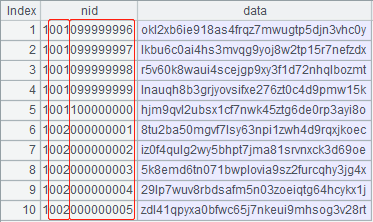
这样就得到了新的“单字段建”的数据结构:
字段名称
| 类型
| 是否主键
| 说明
| nid
| long
| 是
| 包含 type 和 id 信息的唯一主键
| data
| string
|
| 需要获取的数据
|
接下来按照 "单字段键" 中的做法就可以处理了,当然还要注意确保 nid 有序。
注意:
未完,需要接着看下一篇
|
|

 发表于 2018-10-11 11:40:20
发表于 2018-10-11 11:40:20



