42
0
204
中级会员
自定义比较类用于key
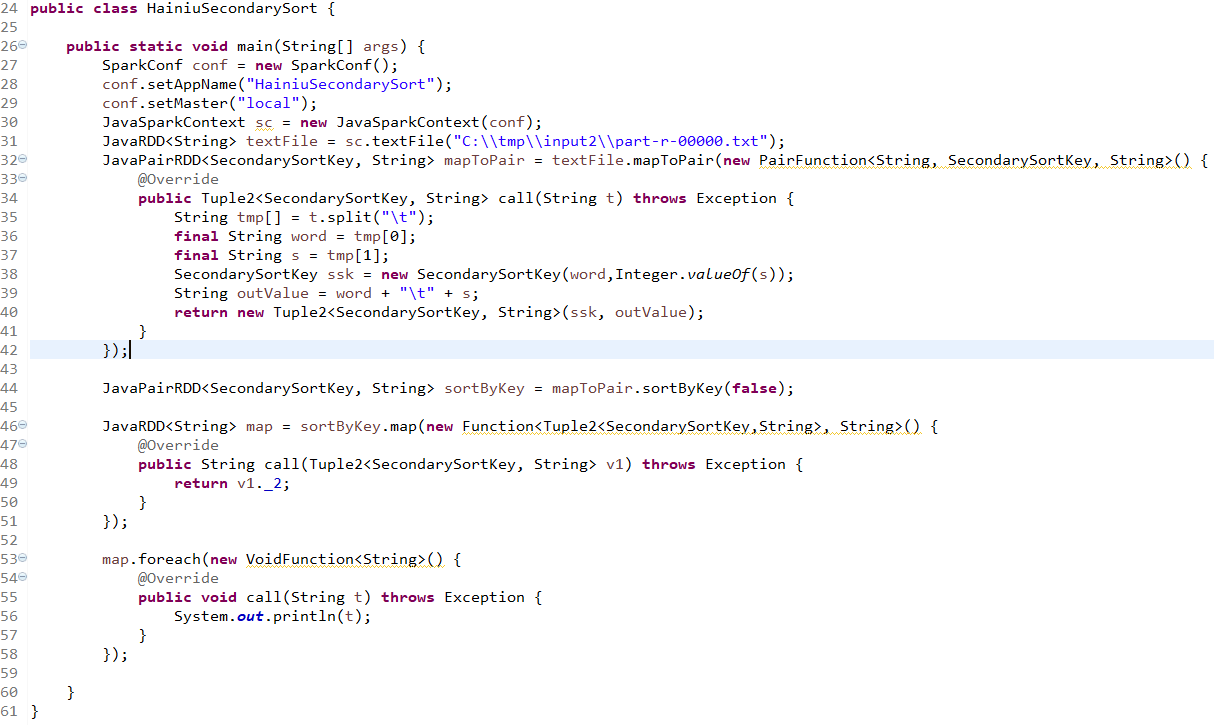
用spark rdd实现二次排序
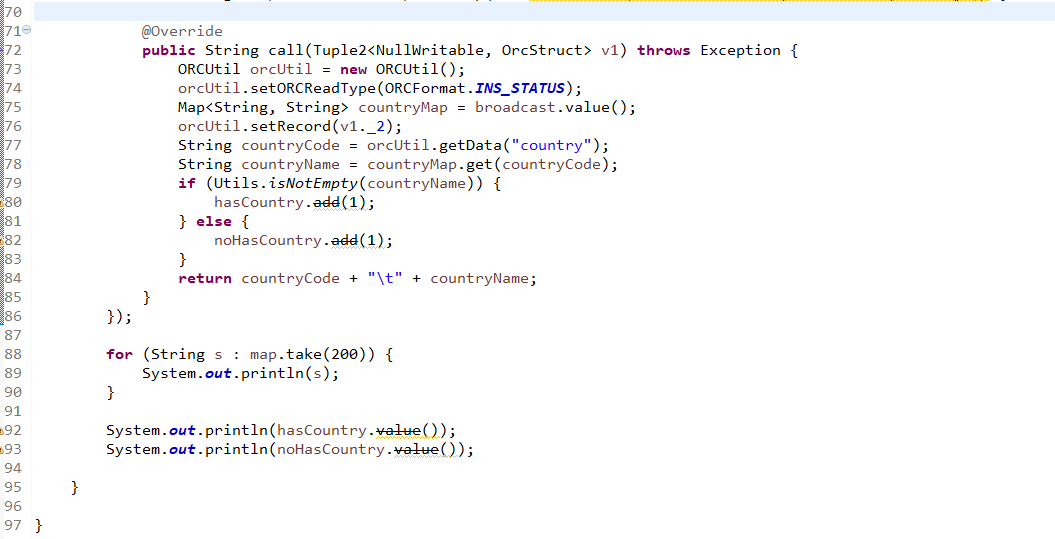
程序结果
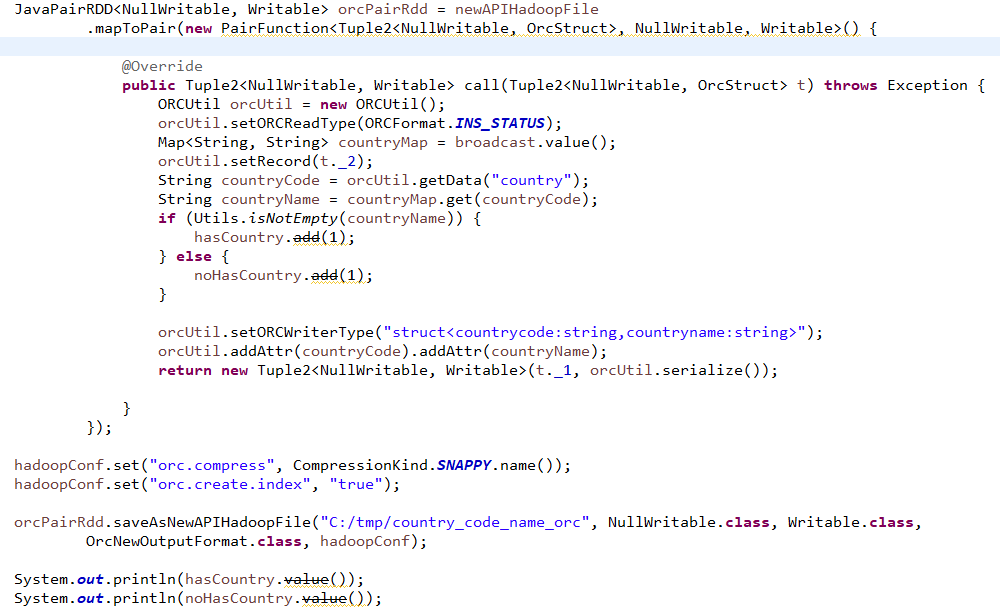
借助之前封装的orcutil,把结果保存为ORC格式的文件,注意输出hadoop格式时要将rdd转成pairrdd
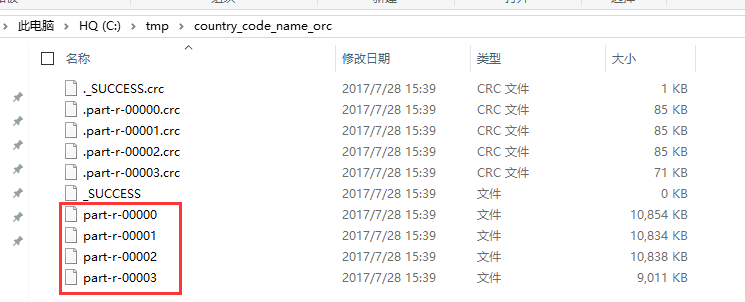
程序运行结果
举报
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
版权所有: Discuz! © 2001-2013 大数据.
GMT+8, 2024-4-20 23:35 , Processed in 0.134638 second(s), 24 queries .



 发表于 2018-3-16 13:55:10
发表于 2018-3-16 13:55:10



